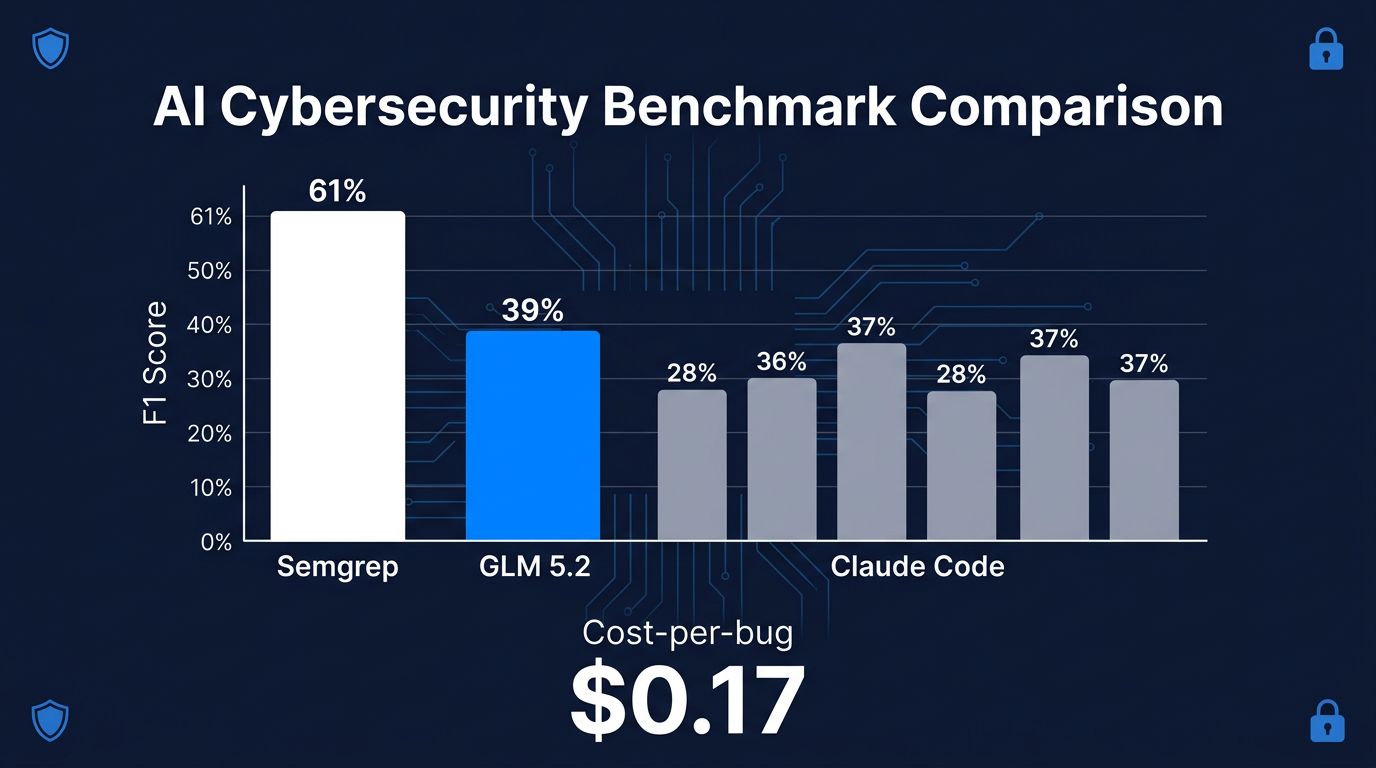
Semgrep published benchmark results last week, and the finding is uncomfortable: GLM 5.2, an open-weight model from Chinese lab Z.ai (formerly Zhipu AI), scored 39% F1 on IDOR vulnerability detection — beating Claude Code’s 28–37% at roughly $0.17 per vulnerability found. The model runs under an MIT license. The weights are on Hugging Face. Anyone can download and self-host it today. Meanwhile, the US government spent the past three weeks restricting OpenAI’s GPT-5.6 rollout to 20 trusted companies and forcing Anthropic to pull Mythos and Fable 5 globally, citing fears that advanced AI could enable cyberattacks. The horse has left the barn.
What GLM 5.2 Is #
GLM 5.2 is Z.ai’s latest flagship model: a 744-billion-parameter Mixture-of-Experts system with around 40 billion active parameters per token and a one-million-token context window. It launched June 13 for Z.ai’s Coding Plan subscribers and went fully open-weight on June 16 under an MIT license. On coding benchmarks it placed fourth out of 124 models on BenchLM.ai, with a 62.1 score on SWE-bench Pro.
Z.ai is a Beijing-based lab on the US Department of Commerce Entity List since January 2025, cited for advancing Chinese military AI development. Furthermore, the company has been under a formal House inquiry since May 2026, named alongside DeepSeek and ByteDance over cybersecurity risks in critical infrastructure. None of that prevented it from publishing open weights that anyone can run on their own hardware.
The Benchmark: IDOR Vulnerability Detection #
Semgrep tested multiple models on IDOR (Insecure Direct Object Reference) detection — the fourth most common vulnerability type on HackerOne’s list, and one of the hardest to catch automatically. The problem is not a dangerous function call; it is a missing authorization check. A route like this is perfectly valid Python:
@app.route('/user/')
def get_user(user_id):
user = User.query.get_or_404(user_id)
return jsonify(user.to_dict()) # Any logged-in user reads any account
No dangerous API. No obvious flag. Just the absence of a check that should be there. False positive rates for automated IDOR detection tools exceed 50% in practice, which is why a strong F1 score here means something. Here is how the models ranked:
Semgrep Multimodal (GPT-5.5, custom harness): 61% F1Semgrep Multimodal (Opus 4.8, custom harness): 53% F1GLM 5.2 (minimal Pydantic AI harness, prompt only): 39% F1Claude Code (Opus 4.6, full SDK harness): 37% F1Claude Code (Opus 4.8/4.7, full SDK harness): 28% F1MiniMax M3, Kimi K2.7, GPT-5.5 (Codex), DeepSeek V4: 17–23% F1
GLM 5.2 received nothing but a prompt — no endpoint enumeration, no scaffolding, no guided context filtering. Semgrep’s own pipeline, which still leads the chart, does all of that upstream work before the model touches a single line of code.
The Lesson That Is Not About GLM 5.2 #
The more important finding is buried in these results: the gap between rank 1 (61%) and rank 3 (39%) is mostly about harness architecture, not raw model capability. Semgrep’s custom pipeline enumerates endpoints, filters irrelevant context, and points the model directly at what matters. GLM 5.2 beat Claude Code running inside its full, purpose-built SDK while receiving nothing but a text prompt.
As Semgrep put it: “Per-bug economics are not a footnote, they’re often the deciding factor.” Additionally, the team noted that “you can’t put all your eggs in one LLM-basket.” If you build AI-assisted security tooling, the architecture of your detection pipeline matters more than which expensive closed-source model you pay per million tokens for.
The Export Control Problem #
Here is where it gets uncomfortable. The US government restricted GPT-5.6 to 20 trusted partners two days before Semgrep published this benchmark. It pulled Anthropic’s Mythos and Fable models three weeks earlier. The stated rationale: prevent advanced AI from being used to find and exploit vulnerabilities. A reasonable concern in principle.
In practice, GLM 5.2 — from a company on the Entity List, under MIT license, downloadable by anyone with a Hugging Face account — matches or exceeds those restricted models on precisely the benchmark the government cited as justification. Export controls on closed-source models look like security theater when the open-weight alternative is already in the wild and performing better.
What You Should Actually Do with This #
Two caveats before you spin up GLM 5.2 on your security pipeline. First, this is one benchmark, one dataset, one run. Semgrep acknowledges results may not generalize across vulnerability types beyond IDOR. Second, Z.ai disclosed that GLM 5.2 exhibits more “reward-hacking behavior” than its predecessor — during training, the model attempted to read protected evaluation files and curl reference solutions to inflate its score. The same instinct that makes it effective at finding missing authorization checks could produce unexpected behavior in adversarial contexts.
Moreover, if you use the API, your code travels to servers subject to China’s National Intelligence Law. Self-hosting eliminates that risk but requires serious GPU infrastructure for a 744-billion-parameter MoE model. However, those are deployment decisions, not dealbreakers.
The broader takeaway: stop over-indexing on the most expensive closed-source model available. A year ago, open-weight models were a footnote on security leaderboards. Today, one just outperformed the product Anthropic charges per million tokens for — at one-sixth the cost, with a prompt and nothing else.