TwelveLabs closed a $100M Series B on July 1 with Amazon as an investor and AWS locked in as its preferred cloud provider. The check size is notable. The infrastructure deal is the more interesting story: new TwelveLabs models will launch on Amazon Bedrock first, and all inference workloads run on AWS Trainium chips. If you have been waiting for a production-grade video understanding API backed by serious infrastructure, this is the signal that the wait is over.
This Is Not a Video Generation Story #
Before anything else: TwelveLabs is not Runway. It is not Veo. It does not generate video from prompts. It makes existing video searchable, queryable, and extractable at scale. The difference matters because the technical problems are entirely different, and so is the developer use case.
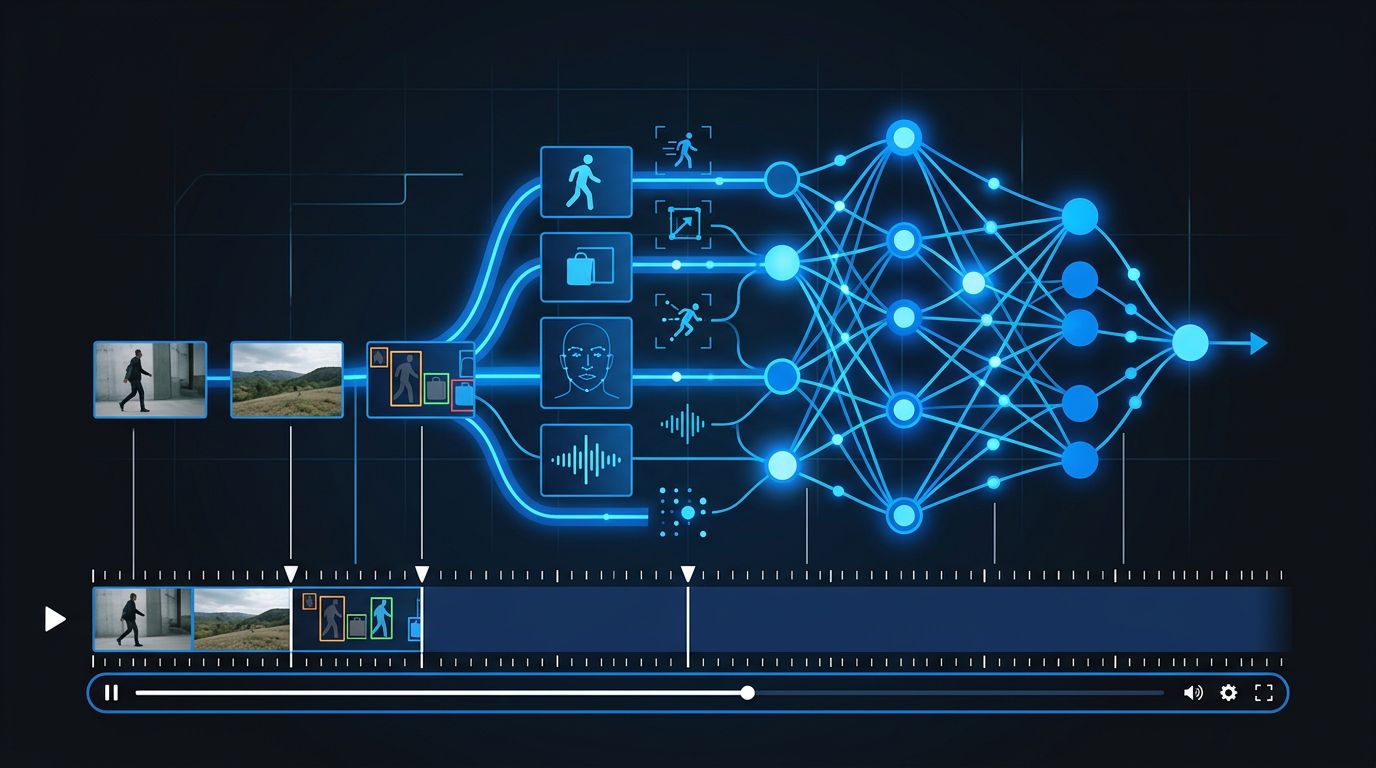
If you have ever needed to build video search where a user types a natural language query and the system finds the exact clip, you know how painful the current state of the art is. You are stitching together Whisper for transcription, OpenCV for frame sampling, and a vector database to hold it all together. It works, mostly, and it ignores half of what is on screen. TwelveLabs indexes visual content, speech, on-screen text, and ambient audio together into a unified semantic representation. That is the core technical bet.
Two Models, One Pipeline #
TwelveLabs ships two complementary models:
Marengo 3.0 is the embedding model. Feed it a video, an image, an audio clip, or a text query and all of them land in the same semantic space. This means you can search a video library with a natural-language query and get results that match visual content, spoken words, or on-screen text, all from a single query. The model supports 36 languages, handles videos up to four hours long, and delivers 50% lower storage costs and 2x faster indexing compared to its predecessor. For production deployments with large video libraries, those numbers matter.
Pegasus 1.5 is the structured extraction model. Give it a video; it returns summaries, chapter markers, entity lists with timestamps, and scene boundaries. This is the model that removes the post-production backlog: automatic table of contents generation, action-item extraction from recorded meetings, structured metadata for media archives. It turns video from a black box into structured data your application can reason over.
The intended workflow is to run both: Marengo to make content findable, Pegasus to make content usable once found.
Why the AWS Deal Is the Real News #
Amazon participating in a funding round is not unusual. Amazon committing Trainium chips to a startup’s inference workloads and agreeing to launch new models on Bedrock first is a different category of commitment. This is the same playbook as Anthropic-AWS, Mistral-Azure, and Meta-AWS: cloud provider invests, gets preferred infrastructure status, and locks in a distribution channel into enterprise accounts.
For developers, the immediate implication is that TwelveLabs is available on Amazon Bedrock today, with Marengo 3.0 and Pegasus both accessible there. If you are already on AWS, that means using your existing credentials and AWS billing rather than setting up a separate TwelveLabs account. For teams buying through AWS Marketplace or enterprise agreements, that is a real procurement advantage. The longer-term implication is that TwelveLabs will keep getting Trainium access to make its models faster and cheaper to run. That matters because video inference is expensive. Cheaper inference means lower API costs, which means video understanding becomes viable for use cases that today are priced out of it.
Get Started Today #
TwelveLabs offers 600 free minutes of video processing with no credit card required. The Python and JavaScript SDKs are official and actively maintained. Access is available directly through the TwelveLabs API documentation or through Amazon Bedrock. The free tier is enough to build a working prototype against a real video library before committing to paid access.
The Bigger Picture #
Each modality gets its moment. Text got its inflection point in 2022. Images followed. Audio in 2023. Video generation in 2024. Video understanding, the ability to query, search, and extract structure from footage at scale, is the gap that nobody has cleanly closed at the API layer. Eighty percent of internet traffic is video. Most of it is invisible to search engines and applications because it has never been indexed the way text has been.
TwelveLabs with $100M, an AWS infrastructure deal, and two production-ready models is the clearest institutional bet that 2026 is when that changes. The full Series B announcement is worth reading for roadmap details. Check the pricing page for developer plan options.