Most engineering teams adopting LLMs focus on the familiar variables: which model to use, how to write the prompt, and whether retrieval-augmented generation improves accuracy. These are reasonable things to optimize. But after running an AI document-processing pipeline through more than 100,000 generation cycles, I found that the failures which actually cost the most time were not prompt failures or model failures. They were infrastructure-level failure modes that do not have clean names in the literature, and that academic benchmarks are not designed to expose.
This article describes three of them. Each has a detection pattern and a mitigation I have tested in production. None of them require a PhD to understand or implement.
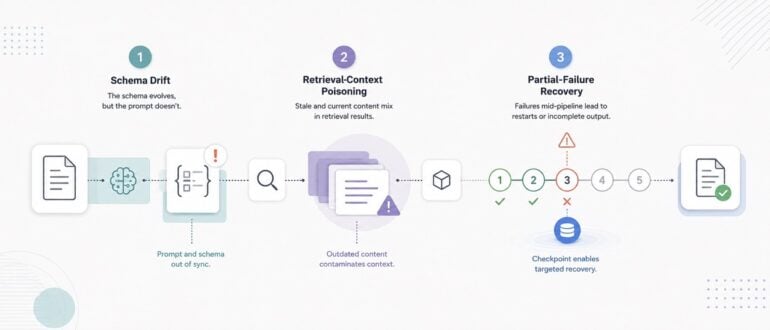
Failure Mode 1: Prompt Drift Under Schema Evolution
Here is what prompt drift looks like. You build a structured-output LLM feature. You write a prompt that reliably produces a JSON object with the fields your application expects. The feature ships. For weeks, maybe months, it works well. Then at some point, a product decision adds a new required field to the output schema. A developer updates the Pydantic model. The database migration runs. And nobody updates the prompt.
The failure is not visible immediately. The LLM is still producing valid JSON. It is just producing valid JSON that matches the old schema, not the new one. Downstream parsing does not crash, because the old fields are still there. The new required field is either missing or filled with a hallucinated value. By the time you catch it, the corrupt data has propagated.
I call this prompt drift because the prompt has not changed but its relationship to the system has. The schema evolved out from under it.
Detection: Add a schema-version field to every prompt. When the application loads a prompt from storage, it checks the schema version embedded in the prompt against the current schema version. A mismatch triggers an alert before any inference runs, not after.
Mitigation: Treat prompts as versioned artifacts in the same way you treat database migrations. When a schema changes, the corresponding prompt change should be a required part of the same pull request, reviewed and merged together. This sounds obvious. In practice, prompts often live in a config file or a database table, not in version control alongside the schema definition, and the connection is invisible during code review.
Failure Mode 2: Retrieval-Context Poisoning
Retrieval-augmented generation systems split documents into chunks, embed those chunks, and retrieve the most relevant chunks at inference time. The assumption is that chunk relevance is stable: if a chunk was relevant last week, it is relevant this week.
That assumption breaks when documents are updated.
Suppose a technical specification is embedded as chunks and used as retrieval context for generating output documents. Later, the spec is revised. A team member updates the source document and re-embeds it. The new chunks replace the old ones in the vector store. But the old chunks may still exist in the store if the deletion was incomplete, if a stale cache is being served, or if the update was applied to the wrong namespace. Now retrieval returns a mix of current and outdated content. The generated output reflects neither version correctly.
I call this retrieval-context poisoning because the retrieval layer is mixing clean and contaminated context in a way that is invisible at the output level. The generated text looks coherent. It is wrong.
Detection: Attach a document hash to each chunk at embedding time. At retrieval time, validate that the hash of the chunk source matches the current hash of the live document. If it does not, flag the chunk as stale before it enters the context window.
Mitigation: Treat chunk deletion as a first-class operation in your document lifecycle. When a source document is updated, the deletion of its old chunks should be atomic with the insertion of the new ones. An update that inserts new chunks without confirming deletion of the old ones should be treated as a failed update, not a partial success.
Failure Mode 3: Partial-Failure Recovery
LLM pipelines often consist of multiple sequential steps: retrieve context, summarize, structure, validate, post-process. A single generation request might touch four or five of these steps in order.
The problem is what happens when step three fails. Typically one of two things occurs. Either the whole pipeline crashes and returns an error, or the pipeline silently skips the failed step and continues with degraded output. Neither is acceptable. A crash requires the user to start over from scratch. Silent continuation produces output that looks complete but has a gap where step three should have contributed.
What most pipelines are missing is granular checkpointing: the ability to record that steps one and two succeeded, step three failed, and step four has not run yet, so that on retry, only steps three and four need to execute.
This matters more than it might seem. In document-generation use cases, steps one and two might involve expensive LLM calls and retrieval operations. Re-running them on every retry is wasteful and slow. More importantly, without checkpointing, step two might produce different output on retry than it did on the original run, which means the output is no longer reproducible.
Detection: Log step start and step end events with a session identifier and a step sequence number. When a failure occurs, query the log to identify the last successful step. This gives you the recovery point without needing to re-run the full pipeline.
Mitigation: Design each step to write its output to a persistent, keyed store before the next step begins. The key is a combination of the session ID and the step sequence number. On retry, the pipeline checks the store for existing step outputs and skips any step that has already completed successfully in this session. This is a standard checkpoint-restart pattern from distributed computing. It is underused in LLM pipeline design, probably because LLM applications are often built incrementally without a formal pipeline abstraction.
What These Failures Have in Common
All three failure modes share a structural property: they are invisible to the testing strategies most teams use. Unit tests for LLM features test individual prompts, not schema evolution over time. Integration tests for RAG systems test retrieval quality at a point in time, not the behavior of the vector store under update. End-to-end tests for multi-step pipelines test the happy path, not the partial-failure case.
This is not a criticism of those testing strategies. They are appropriate for the problems they are designed to catch. The point is that production LLM systems have a class of failures that require operational monitoring, not just test coverage. The failures emerge over time, under load, in the presence of change, in ways that static tests cannot anticipate.
The practical implication is that every LLM feature should be designed with its failure mode in mind before it ships. That means: what happens when the schema evolves? What happens when the source document changes? What happens when the pipeline stalls halfway through? If the answer to any of these is “this gets dealt with when it happens,” that is the failure mode, not the solution to it.
Open Questions
I do not have clean resolutions to all of these problems. Checkpointing works well for sequential pipelines but gets complicated in branching or parallel ones. Hash-based staleness detection works well when documents have stable identifiers, but is harder when the source data is streaming or semi-structured. Prompt versioning solves the schema-drift problem for prompts stored in version control, but does not address prompts generated dynamically or modified at runtime.
These are interesting engineering problems and, I think, underexplored research problems. The gap between how LLM systems are evaluated in the literature and how they fail in production is large enough that production failure taxonomies deserve their own systematic treatment. If you have worked through these failure modes in a different way, I would be interested to hear about it.