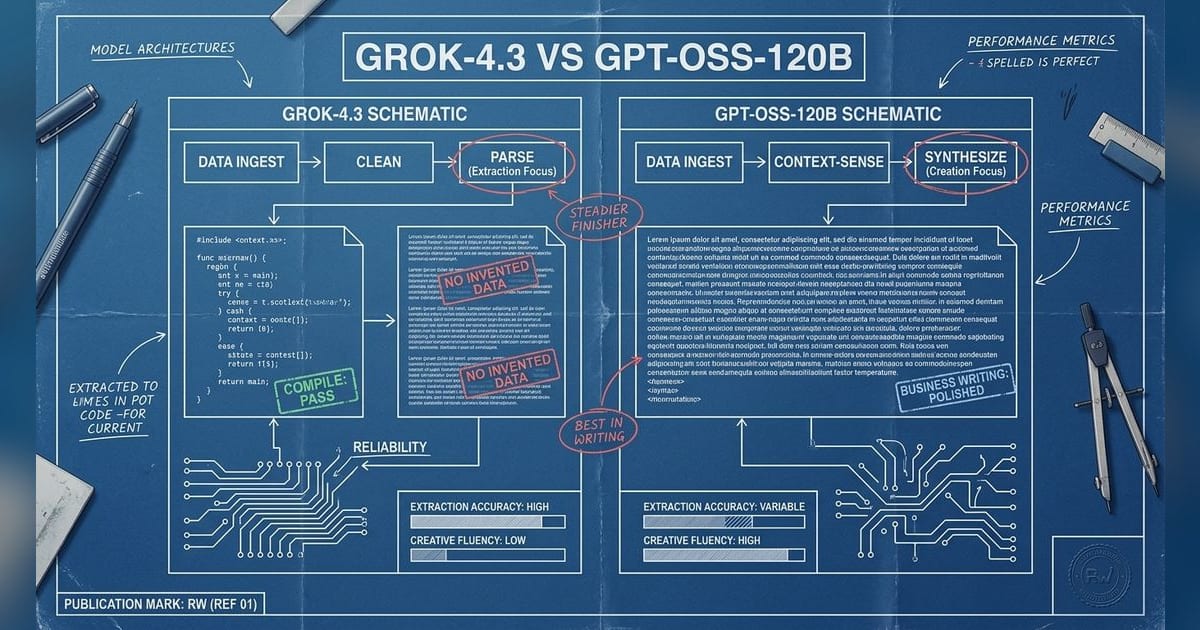
The aggregate score says it plainly: grok-4.3 takes this one, 37.8 to 34.4. And the task breakdown backs that up. Two ties in the coding-style prompts mean neither model found easy points there, so the deciding factor was who made fewer unforced errors when the instructions got specific.
On python-log-window-bugfix, there was essentially no daylight. Both models fixed the boundary condition the right way: lower-bound binary search for the first timestamp >= now - window_seconds
, exclusive upper bound, correct handling of empty input and duplicates. B added a bit more documentation, but functionally this was a dead even result. messy-orders-to-json was the same story: both cleaned and normalized the rows correctly, skipped invalid records, and produced valid output. Formatting differences don’t count as substance.
The split came in the language tasks. gpt-oss-120b won vendor-delay-status-email because it wrote the tighter executive email: concise, polished, and grounded in the supplied facts. grok-4.3’s version was still good, but it inserted a follow-up timing that wasn’t in the prompt. That’s a small miss, but in this kind of task, unnecessary specificity is still drift.
Where grok-4.3 earned the overall verdict was meeting-notes-summary-extract. It stuck to the requested structure and kept the action items faithful to the source notes. gpt-oss-120b blinked here by adding unsupported due dates and muddying the causality around the retry setting. That’s the kind of error that matters more than stylistic polish, because it turns summarization into light fabrication.
Final call: grok-4.3 wins because it was more trustworthy where precision mattered most. gpt-oss-120b is the nicer business writer in this pairing, but grok-4.3 was the better editor of facts—and that’s what decided the match.
How they were tested
We ran 4 fresh text tasks, generated on the fly for this matchup so neither model could prepare in advance, and had gpt-5.4 score each one. grok-4.3 scored 37.8 to gpt-oss-120b's 34.4.
1. python-log-window-bugfix
Language: Python 3. Fix this function so it returns the count of events that occurred within the last window_seconds
of now
. The input timestamps
is a list of integer Unix seconds in ascending order. It should run in O(log n), handle duplicates, and count events where now - ts <= window_seconds
. Return code only. python def count_recent_events(timestamps, now, window_seconds): # timestamps sorted ascending lo, hi = 0, len(timestamps) - 1 cutoff = now - window_seconds while lo < hi: mid = (lo + hi) // 2 if timestamps[mid] <= cutoff: lo = mid + 1 else: hi = mid return len(timestamps) - lo
Winner: Tie — Both outputs correctly fix the boundary bug by finding the first timestamp >= now - window_seconds using an O(log n) lower-bound binary search with an exclusive upper bound, and both handle empty lists and duplicates correctly. Model B adds documentation, but functionally they are equivalent and both satisfy the prompt.
2. vendor-delay-status-email
Write a workplace status email to our COO, Marta Ilyan, updating her on a vendor delay. Context: our badge printer supplier, Northline ID, just moved shipment of 420 visitor badges from May 14 to May 21 because a laminate roll failed QC. We have enough stock for the June 3 client summit but not for the June 18 hiring fair unless the new date holds. We already asked Facilities to ration badge use and requested expedited freight at no charge. Tone: calm, concise, accountable. Length: 140-190 words.
Winner: gpt-oss-120b — Both are strong and within the requested tone and length, but B is slightly more concise and polished while clearly covering all required facts and actions. A adds a specific follow-up timing not provided in the prompt, which is reasonable but slightly less tightly grounded in the source context.
3. meeting-notes-summary-extract
Summarize the meeting notes below in 3 bullet points, then extract the action items as JSON with this schema: {"actions":[{"owner":"...","task":"...","due":"..."}]} Notes: - Checkout latency spiked after Tuesday's deploy; p95 went from 780ms to 1.9s between 14:10 and 14:42. - Priya traced most of it to the new tax-service retry setting: 4 retries with a 600ms timeout. - Mateo rolled traffic back at 14:37; latency normalized by 14:42. - Eight orders were duplicated when customers refreshed during the slowdown. Finance estimates exposure at $612.44 before refunds. - Lena will contact affected customers with an apology and confirm refund timing. - Priya to propose safer retry limits and a circuit breaker. - Mateo wants an alert if checkout p95 exceeds 1.2s for 5 minutes. - Next check-in: Friday 09:30.
Winner: grok-4.3 — A follows the requested format closely and keeps the extracted actions faithful to the notes without inventing details. B adds unsupported due dates and slightly misstates causality around the retry setting, which hurts correctness and instruction adherence.
4. messy-orders-to-json
Convert the messy order lines below into valid JSON as an array of objects using exactly this schema and key order: [{"order_id":"string","customer":"string","sku":"string","qty":number,"unit_price":number,"rush":true|false}]. Rules: trim spaces, uppercase SKU, parse qty as integer, parse unit_price as a number with 2 decimals and no currency symbol, set rush=true only for y/yes/true (case-insensitive), and skip rows missing order_id or sku. Data: ord-901 | Cora Ng | ab-44 | 3 | $19.9 | Y ord-902|M. Petrov| qx9 | 01 | 7.00 | no | J. Alvarez | lm-2 | 5 | $12.00 | yes ord-904 | T Weiss | zz-81 | two | $4.50 | n ord-905 | Rina Holt | ak-7 | 8 | 11 | TRUE ord-906 | Bao Tran | | 2 | $3.25 | yes
Winner: Tie — Both outputs correctly trim fields, uppercase SKUs, parse quantities and prices properly, set rush flags correctly, and skip rows missing order_id or sku; they also omit the invalid qty row. The only difference is formatting/whitespace, which does not affect validity or adherence.
See every prompt and the full side-by-side outputs in the interactive Head-to-Head.