Product Engineer
Product
Hi I’m Matt, I’m one of the product engineers at Adapt building the Adapt agent. We’ve been building a Slack AI agent that connects across all of your apps and interacts with them through tools. Our customers use Adapt to query data, automate actions across apps they use.
We wanted the Adapt agent to be shared. This means everyone in a company uses the same agent. Context is shared across your organization and Adapt does get smarter for everyone the more you use it.
To achieve this, we researched building long term memory for agents. We want Adapt to learn your business process, information, and decisions. If Adapt sees a repeat instruction, it will recognize that pattern and know what to do. We recently shipped out improvements to our memory system, and I wanted to share some techniques we tried.
Explorations of approaches to building memory #
We did some initial exploration by reading about how others are thinking about implementing memory. This article from IBM does a great job describing the different forms of memory. The article called out different subcategories of long term memory (LTM):
- Episodic memory: the ability to remember decisions in the past, and recall that to make decisions in the future.
- Semantic memory: Storing factual information, events, information. Memory of the knowledge base.
- Procedural memory: Store and recall skills, rules, and workflows to help the agent improve efficiency. Remembering the ‘how’ not ‘what’.
Here are some of today’s most popular approaches to implementing a memory system:
Vector embedded memory
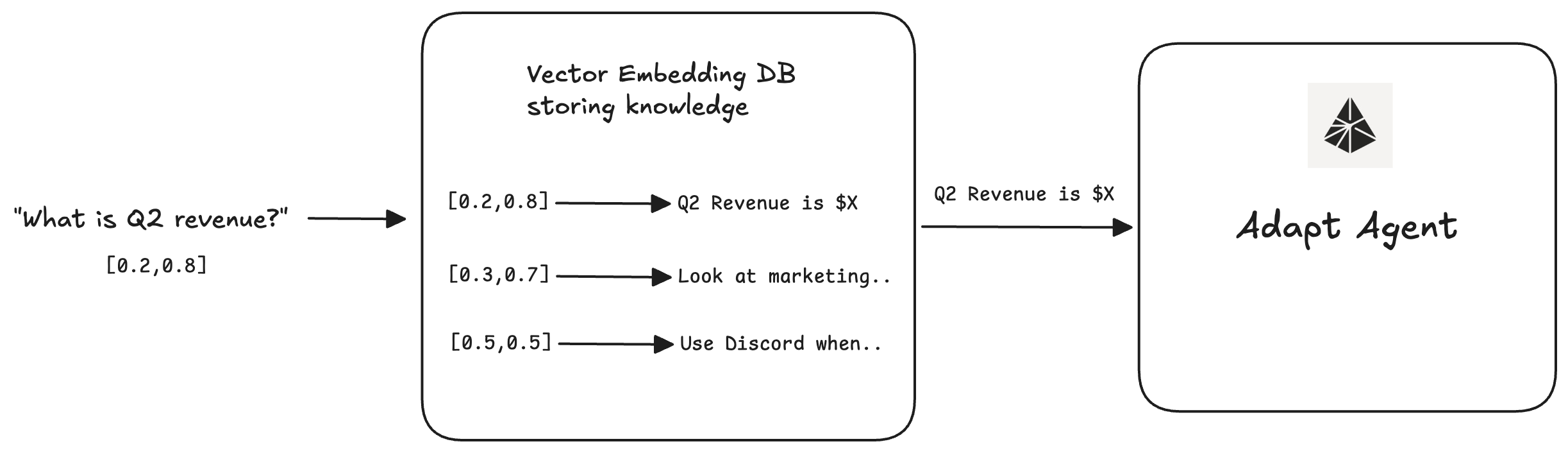
One way of building memory is through using a vector database. When we want to store a piece of memory, it is stored as a semantic embedding in the vector database. On retrieval time, the agent will query that vector database with a similarity search such as cosine similarity.
Vector embedding storage and retrieval is very cheap to run and scales, which is why this approach is popular. It falls short on understanding memory relationships, and expiring outdated information.
Filesystem / Graph memory
Agents are given read, write, traversal tools that they can use to browse through a filesystem and search for context. When an agent creates or updates a memory, it finds a relevant file in the filesystem and creates / updates a markdown file. Information has a hierarchy and is relational instead of fragmented.
Filesystems don’t scale to millions of records, and retrieval is more expensive as the agent has to traverse the filesystem to find and read the relevant memories.
Storing semantic memory in vector DB isn’t enough #
Our first attempt at company-wide memory was storing semantic memory. We did this through a vector embedding store.
Here’s the flow of how memory is retrieved:
- The user query is converted into chunks for retrieval.
- Using those user query chunks, we run a cosine similarity search on the vector DB to retrieve the top k similar knowledge results. We filter out knowledge that does not meet a similarity threshold.
- We load the remaining knowledge chunks into the conversation context.
Here’s the flow for memory storage:
- The agent has a
save_knowledgetool that it can use to save knowledge snippets, with guidance on how to generate keywords for the embedding, and creating the content to save. The agent also has guidance in its system prompt on what to save / not save. - On every turn, the Adapt agent can choose whether or not to save knowledge. When it wants to save knowledge, it will call the tool. The tool then creates a new org-wide knowledge entry with the embeddings.
A semantic memory system like works great as a memory cache. Rather than having to call integrations to fetch information at every turn, this system loads up relevant memory on the fly, saving tokens and speeding up turns.
There are two main weaknesses to this memory approach. First is that the information stored in this memory cache can be outdated. We have no way of knowing whether or not a piece of memory is up to date, unless we re-fetch that information from the source. The second is that vector embeddings don’t always pull up relevant results. A cosine similarity search returns the top N best guesses, but there’s no guarantee that these results are relevant. We’ve seen instances where memory retrieved is completely irrelevant from the original request.
Company wide memory #
Recently, we’ve been experimenting with the concept of global company-wide memory. It’s a single markdown-like file that is shared and always injected into the context. The Adapt agent deployed in your company are accumulating knowledge about how you run your company, then building a mapping of that in the company-wide memory.
We considered context implications when storing company-wide memory. Since it’s a shared doc and always loaded into context, we have to be picky about what knowledge we choose to store. The knowledge must be durable (true for months), useful context for company operations, and guide the Adapt agent to provide the correct answers.
We decided on the following categories on what to store:
- Org structure - Who does what, who is in charge of what
- Processes - How the company operates
- Data and systems topology
- Vocabulary
- Decisions and policies
A full company wide knowledge doc might look like the following:
# Adapt global knowledge
This is shared tribal knowledge of how Adapt's company operates. Anything not in here, use the tools / integrations you have for lookup.
## Policies (always apply)
- External customer comms must be reviewed by Marketing before sending.
- #general is announcements-only. Never post there.
- Issue tracking is Linear. Do not suggest or use Jira.
- Never paste customer PII or secrets into a chat. Pull it live, reference by ID.
- Production DB writes require sign-off from the owning team's eng lead.
## Org map (who owns what / who to ask)
`- Payments — billing, invoicing, Stripe integration. Lead: Sarah Chen (eng).`
`- Metering — usage ingestion + aggregation pipeline. Lead: Diego Park (eng).`
- Growth — acquisition, onboarding, lifecycle email. Lead: Priya Nair.
- Data — owns the Snowflake warehouse and all analytics models.
- Escalation: production incidents -> on-call in #incidents; billing disputes -> Finance.
## Where things live (source of truth)
- Revenue & finance metrics: Snowflake finance.* (query live; do not cache numbers).
- Usage/metering data: Snowflake metering.events, rolled up in metering.daily.
- Issues & incidents: Linear (incidents use the incident label).
- Product specs & PRDs: Notion "Product" space.
- Support tickets: Zendesk. Account health & contract terms: Salesforce.
- Release announcements: #eng-releases. Customer-facing changelog: Notion "Changelog".
## Definitions & vocabulary
- ARR = committed annual contract value, excluding one-time and usage overages.
- Active org = an org with at least one API call in the last 28 days.
- Project Atlas = the in-progress billing-engine migration (target Q3).
- Fiscal year starts in February.
## How we operate (key recurring processes)
- Deploy: merge to main -> CI -> manual approve in #eng-releases. Owner: eng lead of the service.
- Incident: open a Linear issue with incident, post in #incidents, assign on-call.
- Weekly metrics review: Mondays; numbers pulled fresh from Snowflake finance.*.
(Full step-by-step procedures live as individual entries — look them up when running one.)
What’s next #
Today, both memory systems work in tangent together to make up Adapt’s memory system. Some of the future improvements to memory that we are exploring at the moment:
- We're looking into creating a background job that is constantly running, scanning through your data sources to make sure that the memory cache layer is up to date. This would consist of looking at old memory pieces, spinning up a background agent to scan and verify whether or not that snippet of knowledge is up to date.
- For company-wide knowledge, creating a database that stores company-wide knowledge indexed on the creator and category, over using a single markdown-like file. This will help with handling collisions when it comes to editing company-wide knowledge and granular controls on what should be retrieved into the context from the knowledge.
You might also like #
Loops for the whole team: agentic workflows beyond the coding agent
Loops are goal-directed AI workflows that run without constant prompting. What they really are, where the hype breaks down, and how teams can apply them well.
Chasing Fable
A long, long time ago, about 2 weeks to be precise, in a land called San Francisco a new model was dropped by a company named Anthropic.
Our favorite AI tools for marketing
Our favorite AI marketing tools that integrate with AI agents.
Every company will have a brain. #
It's inevitable.
Get started in minutes, not months.