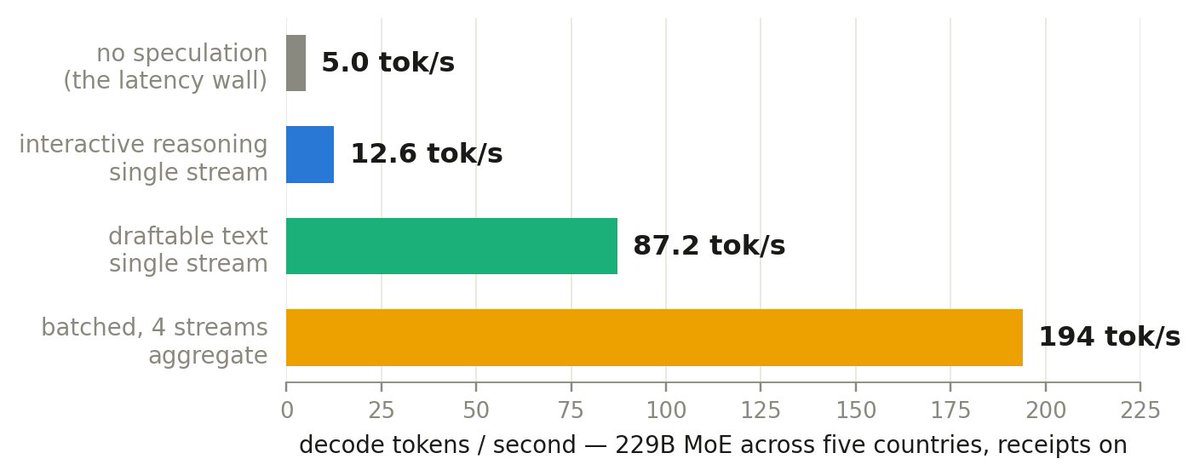
1/ We published our first technical report today. We ran a 229B model split across five consumer GPUs in five countries over the public internet and measured 12.6 tok/s interactive, 194 tok/s batched. With cryptographic receipts on every request. doi.org/10.5281/zenodo…
source & further reading
twitter.com — original article