Why I think Yann Lecun was right about LLMs (but perhaps only by accident)
It’s become very popular over the last few years to speculate how close society might be to *Artificial General Intelligence *(AGI). What AGI actually means is murky, and often-debated, but mentioning AGI is usually a good jumping-off point for discussions of future artificial intelligences’ capabilities. Many following the field maintain AGI timelines, rigorous guesses for the probability of this mythical intelligence to emerge at future points. Those in the know might ask you for your timelines over coffee, classifying them as “long” – that it might be a decade or two before AIs are smart enough to take all of our jobs – or “short” – that it could happen any day now.
This isn’t the most useful way of thinking about the progression of AI capabilities. The existence of a timeline implies AGI has a rigorous definition and can be measured. It also implies that AGI is inevitable, the only question being when it will arrive.
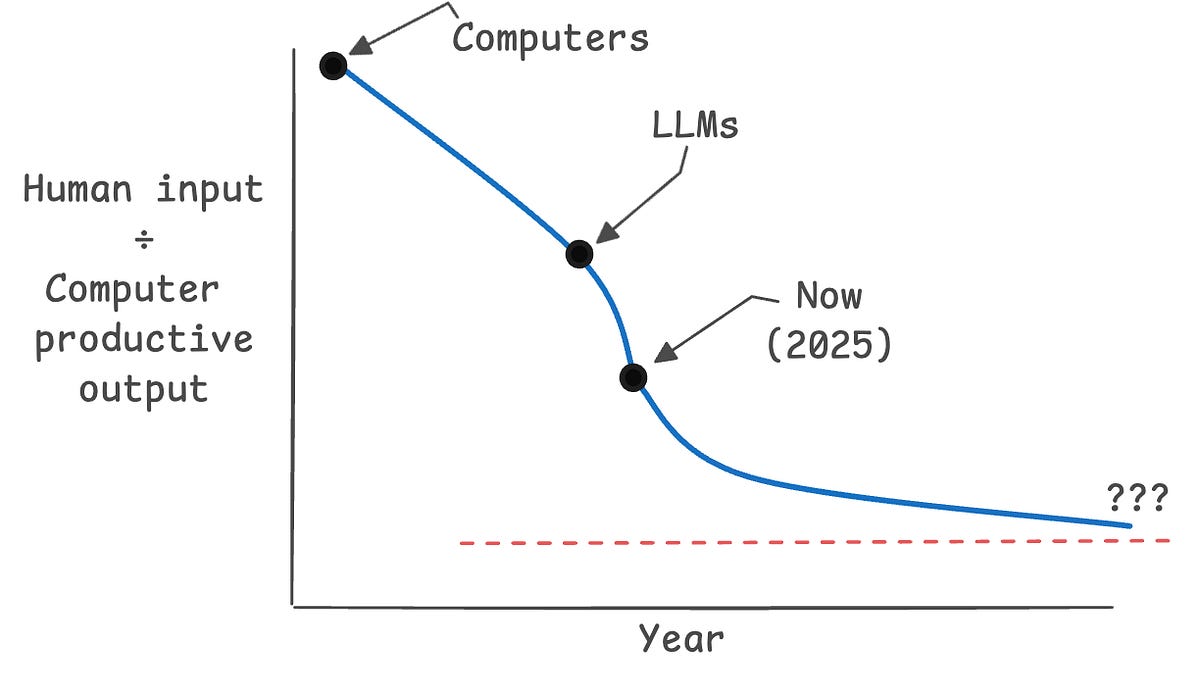
What I see is not a march towards complete general intelligence, but rather a trend of increasing AI productivity per unit of human input. This trend holds across many disparate applications. Our AIs can label more data, write more code, do more math, as well as drive cars and pilot planes for longer with less intervention from us. It may be possible that we’ll never reach a point where AIs can run forever, uninterrupted, without human guidance. Rather we’re pushing the boundary of how much we can get for what we give.
Instead of talking about the mythical final frontier of AGI, I think we should start thinking more realistically and measuring the ratio of human input per useful AI output.
Imagine for a moment the curve of how much we input have to provide for a unit of economic value the computer produces, and how this has changed over time. A very rough estimate is pictured above; one important open question is whether we’re approaching some unknowable carrying capacity, or if this figure will eventually decay to zero. (If this happens, it means that computers will be able to produce economic value with zero human input. This would be a frightening outcome.)
To understand what I mean better, let’s take a trip back in time to 2017…
**We’ve seen this before (in self-driving cars)**
If you’re new to the AI field, you should know that before language models, there was a previous AI craze circa 2017: the rise (and fall?) of the self-driving car.
If you’re not new to AI, let me remind you.
Around that time, several companies declared that within a year they would have Fully Self-Driving cars. Billions of dollars were raised. Millions of miles were driven. Many companies were founded, some of which eventually went bankrupt.
And years later, we’re still not quite at FSD. Teslas certainly can’t drive themselves; Waymos mostly can, within a pre-mapped area, but still have issues and intermittently require human intervention.
In response, the field has moved on from speculating the exact point cars will be fully-self driving. People instead discuss miles-per-disengagement (or miles-per-human-intervention). How far can the car drive without a human getting involved? This new lens gives us something that we can measure and track over time. Better technology gives us more miles driven per necessary human action.
What does the future look like for FSD? A recent report said Teslas can drive thirteen miles per human intervention; this estimate feels a little low to me, but still seems pretty good. We can certainly drive this number up with bigger models, faster inference, more data, and improved overall engineering.
A crucial question is whether with current technology, the miles-per-intervention number is bounded by some theoretical limit we don’t understand. We don’t know whether our models will keep getting better forever (approaching infinite miles driven with no interventions) or if there really is some amount of human intervention that will always be necessary.
Why Yann Lecun was wrong (kind of) Now let’s apply this idea to today’s AI craze: language models.
A few years ago, Meta’s Chief AI Scientist Yann Lecun gave a talk about how language models won’t give us a direct path to human-level intelligence. He argued that because language models generate outputs token-by-token, and each token introduces a new probability of error, if we generate outputs that are too long, this per-token error will compound to inevitable failure.
Yann has used this simple argument to explain to the masses why we shouldn’t work on language models if we care about achieving human-level AI. He presents this problem of compounding errors as a critical flaw in language models themselves, something that can’t be overcome without switching away from the current autoregressive paradigm.
But this has turned out to be wrong. A few new AI systems (notably OpenAI o1/o3 line and Deepseek R1) contradict this theory. They are autoregressive language models, but actually get better by generating longer outputs:
The finding that language models can get better by generating longer outputs directly contradicts Yann’s hypothesis. I think the flaw in his logic comes from the idea that errors must compound per-token. Somehow, even if the model makes a mistake, it is able to correct itself and decrease the sequence-level error rate. This is an incredible development, and was not the case with prior generations of LLMs.
And it turns out that the models’ mechanisms for correcting themselves are interesting and interpretable:
As shown in the image, models can in fact increase their likelihood of success mid-sequence by generating specific strings of tokens. A cottage industry of research is emerging trying to characterize and induce these behaviors, such as “backtracking” to a better solution. (It’s worth noting here that we still don’t know how generalizable these techniques are outside of the types of problems these models were trained on, like coding and math problems.)
Why Yann Lecun was right (kind of) Naturally, people have been upset about all this. One of the founding members of the field has been giving bad advice to early-stage researchers based on a busted intuition. It’s infuriating, right?
Well, not exactly. I think that people are taking Yann’s argument a little too literally. Yes, we’ve figured out a way to build language models that don’t strictly get worse as we use them to generate longer outputs. But the limiting behavior remains the same: eventually, if we continue generating from a language model, the probability that we get the answer we want still goes to zero.
The practical takeaway from this is that AIs can’t work on their own forever. Lots of people are working on building Agents, systems that use language models to accomplish tasks over long time horizons. But the quest for a fully autonomous agent feels similar to the quest for fully self-driving cars: it might never be possible to build this, at least with the current stack.
There may be a kind of data processing inequality going on behind the scenes. In some sense, the highest-quality information inputted to language models comes from the human-written prompts (and potentially inputs read in via tool use, like checking flight times or the weather). When the language models are left on their own to generate infinitely-long chains of thought, that input “signal” attenuates to nothing; eventually, without further input from a human, those chains of thought lose all meaningful value. Improving our technology can delay this, and improve the quality and amount of work we can do with a single input prompt. But it doesn’t seem likely that I’ll wake up one day next year and this figure (work / prompt) will have spiked to infinity.
This is why measuring language models’ progress in terms of AGI timelines is misguided. We should be thinking about language models the same way we think about cars: How long can a language model operate without needing human intervention to correct errors? Framing our inquiries into language models like this allows us to reconcile Yann’s valid concerns about the models with new advances from OpenAI and DeepSeek—and will also lead to more productive research and conversation in the language model field, as it has with cars.
Instead of waiting for FAA (fully-autonomous agents) we should understand that this is a continuum, and we’re consistently increasing the amount of useful work AIs can do without human intervention. Even if we never push this number to infinity, each increase represents a meaningful improvement in the amount of economic value that language models provide. It might not be AGI, but I’m happy with that.