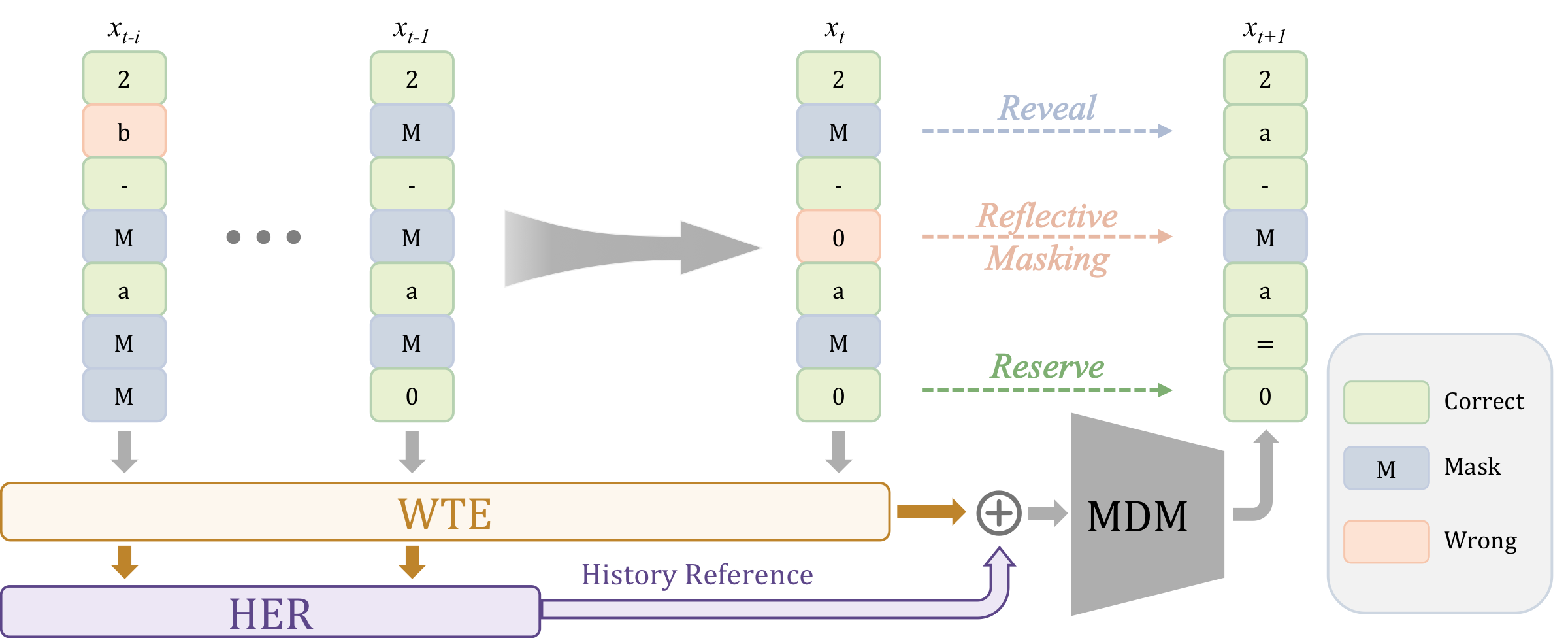
TL;DR — Reasoning by editing, not regenerating. Reflective Masking turns a Mask Diffusion Model into a multi-turn reviser: it erases uncertain tokens, regenerates only what is needed, and remembers previous attempts.
Abstract
Recent diffusion language models — such as Google's DiffusionGemma — show that text generation need not be left-to-right: a model can refine a whole canvas using bidirectional context. We ask a complementary question: can
existing
Mask Diffusion Models (MDMs) be taught to reason by revising their own previous outputs? We propose
Reflective Masking (RM), a lightweight post-training method that turns masking into a model-driven decision — keep reliable tokens, re-mask uncertain ones, and reveal better replacements — making an MDM a multi-turn reviser rather than a one-shot decoder. To support multi-turn correction we add
History Reference, a parameter-free memory that exposes the denoising trajectory to the model. Unlike a large pretrained diffusion LM, RM needs no architectural changes and no online rollouts, and drops into existing MDMs across
Sudoku, text reasoning, and image editing— enabling sparse, iterative self-revision.
- 1 Re-masking is the self-correction MDMs were missing. MDMs can edit in place but neverchooseto — so they lock in early mistakes. RM makes masking a model-driven decision (keep reliable tokens, re-mask uncertain ones, reveal better replacements), so the model fixes its own errors instead of carrying them forward. - 2 A lightweight post-training recipe — no new architecture. RM is activated by a scalable offline data pipeline (no online rollouts) and drops into existing MDMs unchanged — validated across text, Sudoku, and image editing. - 3 History Reference — a memory of past attempts, for free. A parameter-free mechanism that carries the denoising trajectory forward, so the model remembers what it already tried and stops repeating the same error.
CoT thinks by continuing. RM thinks by revising.
A diffusion-native analogue of chain-of-thought reflection.
Side-by-side: AR Reasoning vs. Reflective Masking Reasoning #
| AR reasoning / reflection | Reflective Masking in MDMs |
|---|---|
| Generates thoughts left-to-right | Revises a full canvas bidirectionally |
| Corrects mistakes by appending more text or regenerating | Corrects mistakes by re-masking only unreliable tokens |
| Past mistakes remain in context | Wrong tokens can be erased from the current state |
| Test-time scaling = longer traces / more samples | Test-time scaling = more rounds of selective revision |
| Memory is textual context | Memory is History Reference over denoising states |
Results
Reasoning through explicit revision #
Three task families, from instruction-rich image editing to open-ended text reasoning. Reflective Masking consistently beats masking-based baselines, and History Reference helps most where the model must explore on its own — all trained in about 5 hours on 2×H100.
Sudoku — structured error correction
A tiny from-scratch MDM (0.81M params) recovers 9×9 boards with 4–20 corrupted cells by iterative re-masking. History Reference (HR) sharply cuts repeated mistakes and rule conflicts; adding History Embedding Rotation (HER) tops every metric.
| Variant | Exact Accuracy % ↑ | Valid Rate % ↑ | Replay Mistake % ↓ | Conflict Cells /board ↓ | |---|---|---|---|---| | RM (no History Reference) | 82.4 | 86.6 | 0.57 | 0.578 | | RM + HR | 91.4↑9.0 | 91.8↑5.2 | 0.07↓0.50 | 0.300↓0.278 | | RM + HR + decay | 89.4↑7.0 | 89.6↑3.0 | 0.07↓0.50 | 0.362↓0.216 | | Ours — RM + HR + decay + HER | 93.4↑11.0 | 93.6↑7.0 | 0.03↓0.54 | 0.236↓0.342 |
Quantitative results on Sudoku revision. Δ is the change versus the RM (no History Reference) baseline; bold marks the best value per column.
Relation to DiffusionGemma (Google). DiffusionGemma independently validates reasoning-by-revision on Sudoku: per its model card, exact-solve rises from 18% one-shot → 89.5% purely by revising over steps, and from 1.5% → 89.5% after fine-tuning a large pretrained model for 4,000 steps. Reflective Masking reaches an even higher 93.4% exact accuracy with a 0.81M-parameter MDM trained from scratch — orders of magnitude smaller than DiffusionGemma's fine-tuned backbone — and extends the same revision mechanism beyond text to image editing, a modality DiffusionGemma does not support.
DiffusionGemma: Google, “DiffusionGemma: 4× faster text generation” (2026); Sudoku numbers from the fine-tuned model card (Unsloth).
Image editing — localized, instruction-guided revision
With a 7B multimodal backbone (Lumina-DiMOO), Reflective Masking localizes the edit and changes only that region, leaving the rest of the image untouched — outperforming masking-based baselines.
Text reasoning — self-correction with no answer hints
On open-ended math and code (LLaDA backbone), the model re-masks uncertain intermediate tokens and revises them as context resolves — beating both the base model and vanilla SFT.
A diffusion-native analogue of reflection. Chain-of-thought and reflection let autoregressive models reason by writing more — appending a new trace and carrying every past mistake along in the context. Reflective Masking gives MDMs the complementary move: reason by revising. Rather than append a fresh reasoning trace, the model edits its previous state, re-masking only the tokens it now doubts so wrong steps are erased instead of accumulated.
| Benchmark | Category | LLaDA % | Vanilla SFT % | Ours (RM) % | Δ | |---|---|---|---|---|---| | MATH500 | Math | 19.4 | 22.4 | 24.8 | ↑2.4 | | MBPP | Code | 28.0 | 30.6 | 39.4 | ↑8.8 | | ARC-Challenge | MCQA | 73.7 | 81.3 | 86.1 | ↑4.8 |
Performance across benchmarks. Δ is the improvement over Vanilla SFT; bold marks the best value per row.
| Minerva MATH | Algebra | Count. & Prob. | Geometry | Interm. Alg. | Num Theory | Prealgebra | Precalc | Aggregate |
|---|---|---|---|---|---|---|---|---|
| Vanilla SFT (%) | 28.90 | 17.72 | 20.67 | 13.07 | 17.41 | 36.28 | 14.10 | 22.62 |
| Ours RM (%) | 29.49 | 18.35 | 20.67 | 14.40 | 21.67 | 38.00 | 16.67 | 24.10 |
| Δ (%) | ↑0.59 | ↑0.63 | 0 | ↑1.33 | ↑4.26 | ↑1.72 | ↑2.57 | ↑1.48 |
Per-subject breakdown on Minerva MATH; Reflective Masking improves on nearly every category.
Method
Reflective Masking & History Reference #
Each position takes one of three actions per step: Reveal a confident prediction, Reflectively Mask an uncertain one for another try, or Reserve it. Masking becomes a model-driven decision, so the model can revisit and fix its earlier predictions across turns.
History Reference (HER) accumulates per-step states at the embedding level, giving the model access to its own trajectory — what it predicted and what it already revised — with no extra parameters and no longer attention sequences.
Training
Activating Reflective Masking, offline #
RM is taught offline, with no online rollouts. From a clean target we sample a mask, take one MDM forward pass, and draw plausible wrong tokens to build a pseudo-trajectory that matches the model's own distribution. Three per-token losses then teach when to commit, when to re-mask, and when to leave a token alone:
- Revealmasked token → correct token - Re-maskwrong visible token → MASK - Keepcorrect visible token → itself
Citation
BibTeX #
@misc{zhang2026multiturn,
title = {Multi-Turn Reflective Masking Elicits Reasoning in Mask Diffusion Models},
author = {Zhang, Yanming and Bian, Yihan and Qi, Jingyuan and Yao, Yuguang and Huang, Lifu and Zhou, Tianyi},
year = {2026},
eprint = {2606.16700},
archivePrefix = {arXiv},
url = {https://arxiv.org/abs/2606.16700}
}