On June 12, the US government gave Anthropic six hours to disable Fable 5 globally. Not certain regions. Not specific users. All of them. Developers who had Fable 5 wired into production pipelines found out from an API error, not a migration email. Today is Day 15 and the model is still gone. Yesterday, GPT-5.6 Sol launched — but only to 20 government-approved partners, with no public waitlist and no timeline for broader access. The pattern is no longer deniable: governments are now active participants in AI model access decisions. If your application depends on a single AI provider, you have a single point of failure you don’t control and cannot predict.
This is the architecture that changes that.
The Risk Is Bigger Than One Ban #
The Fable 5 shutdown was extreme in its speed — six hours from directive to global lockout — but the underlying fragility was already there. According to Ookla’s reliability data, high-signal AI disruption events across major platforms jumped from 6 in Q1 2025 to 51 in Q1 2026. That trajectory puts enterprises on course for over 200 disruption events this year. Even on a good month, Claude.ai’s measured uptime of 99.32% translates to roughly five hours of downtime.
The Fable 5 ban introduced a category of failure that has no equivalent in traditional infrastructure: regulatory takedown. Technical outages are recoverable with retries and timeouts. A government export-control directive gives you no such handle. Your retries will fail indefinitely. Your circuit breaker will never trip back. The model is gone until it isn’t, and you won’t get advance notice of either event.
GPT-5.6 Sol’s restricted launch the following week is not a coincidence. It is the same logic applied by the same actors. AI models that push the frontier of capability are now subject to a government review layer that did not exist twelve months ago. That layer will not go away.
The Multi-Provider Gateway Pattern #
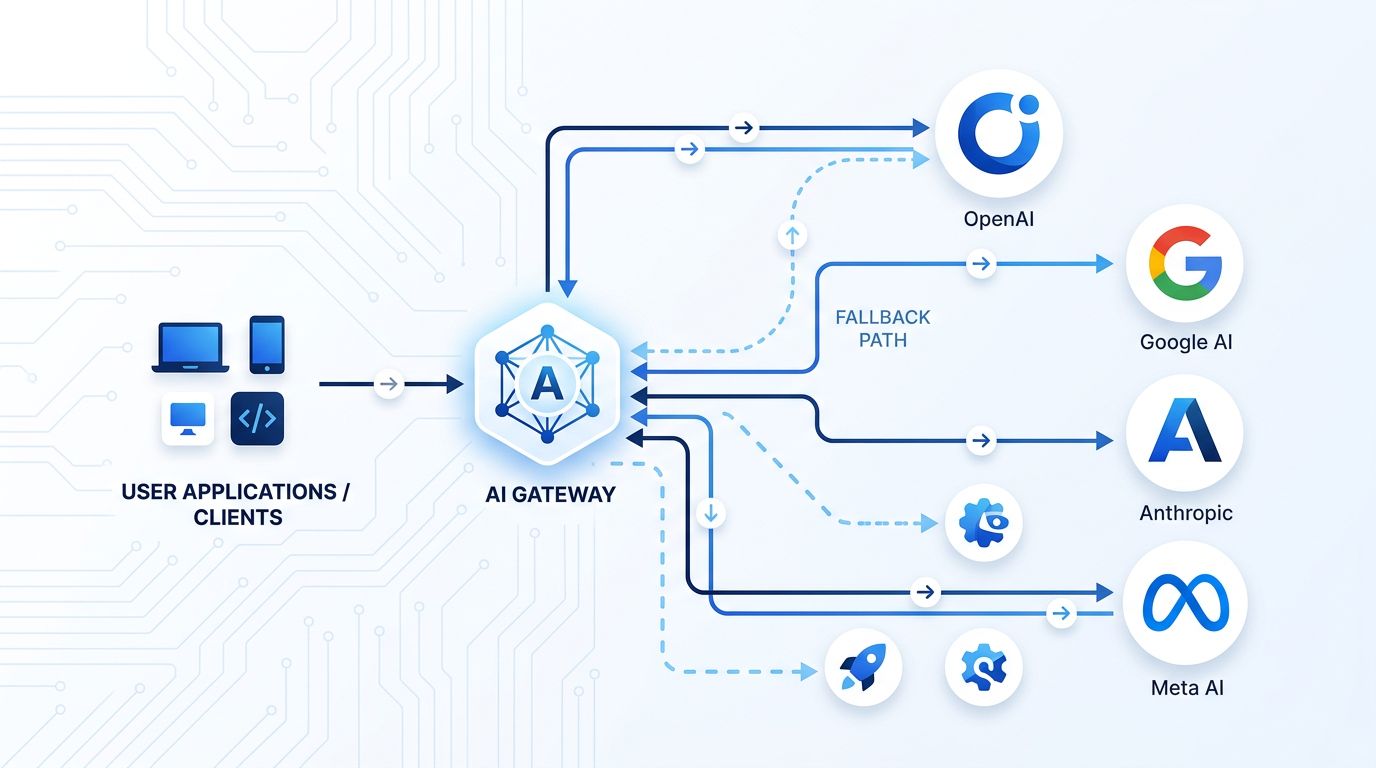
The architectural response is a gateway that sits between your application code and the model providers, routing requests through a priority stack with automatic fallback. Your code calls one endpoint. The gateway handles the rest.
A production gateway needs four layers:
Routing— selects the primary model based on cost, latency, or task type** Authentication**— manages credentials per provider, rotates keys without touching application code** Rate limiting**— prevents exhausting any single provider’s quota** Fallback**— catches errors from the primary and transparently re-routes to the next tier
The most direct open-source path is LiteLLM, which exposes a unified OpenAI-compatible interface to 100+ providers and handles fallback natively. A working router is about ten lines:
from litellm import Router
import os
model_list = [
{
"model_name": "primary",
"litellm_params": {
"model": "claude-opus-4-8",
"api_key": os.environ["ANTHROPIC_API_KEY"]
}
},
{
"model_name": "fallback-1",
"litellm_params": {
"model": "gpt-5.5",
"api_key": os.environ["OPENAI_API_KEY"]
}
},
{
"model_name": "fallback-2",
"litellm_params": {
"model": "zhipu/glm-5.2",
"api_key": os.environ["ZHIPU_API_KEY"]
}
},
]
router = Router(
model_list=model_list,
fallbacks=[{"primary": ["fallback-1", "fallback-2"]}],
num_retries=2
)
response = router.completion(
model="primary",
messages=[{"role": "user", "content": prompt}]
)
Your application code does not change. If Anthropic goes dark — for any reason — the router moves to GPT-5.5. If that fails too, it moves to GLM-5.2. If you prefer a managed path, OpenRouter saw its traffic spike the day Fable 5 was pulled, which means it is battle-tested under exactly the scenario you are planning for.
The Three-Tier Model Stack #
The model stack matters as much as the routing layer. Structure it in three tiers:
Tier 1 — Primary: The highest-capability model available today. Claude Opus 4.8 sits at 88.6% on SWE-bench Verified and 93.6% on GPQA Diamond. GPT-5.5 is a strong alternative if you want US provider diversity from day one.
Tier 2 — Fallback: Near-frontier models from a different jurisdiction or parent company than Tier 1. Gemini 3.1 Pro (Google) and GPT-5.5 (if not in Tier 1) are the natural choices. The goal is provider diversification, not just model diversification.
Tier 3 — Sovereign: Open-weight models that run independently of any US-gated API. This tier is the one lesson the Fable 5 ban adds that no previous outage could have taught. Government directives apply to API providers. They do not apply to model weights you run yourself.
Three credible Tier 3 options available today:
(Zhipu AI / Z.ai) — 744B parameters, MIT license, one-sixth the cost of frontier closed models, 300 tokens per second. Claimed the top BridgeBench Reasoning spot the same week Fable 5 was pulled.GLM-5.2Kimi K2.7-Code(Moonshot AI) — 1T parameter MoE, $0.95 per million tokens, strong agentic stability across long sessions.** MiniMax M3**— $0.30 per million tokens, 1M context window, the lowest-cost credible fallback available.
Be clear-eyed about the gap: a 21-point spread on SWE-bench Pro still separates the best open-weight models from where Fable 5 was. Open weights handle most production workloads fine. They do not fully substitute for frontier reasoning on the hardest tasks. Build your Tier 3 knowing it is an emergency lane, not a drop-in replacement.
Build This Before the Next Ban #
The cloud architecture lesson of the last decade was that assuming a single region would always be available is an engineering mistake, not a cost saving. Multi-region deployment stopped being optional when AWS us-east-1 outages became regular calendar entries.
The AI version of that lesson is arriving now. The Fable 5 ban was not a one-off anomaly. Anthropic’s own statement acknowledged that the US government’s new standard, if applied consistently, would halt frontier model deployments industry-wide. That standard is not being withdrawn. It is being written into policy.
A multi-provider gateway is not an overengineering choice at this point. It is the minimum viable architecture for any AI feature that needs to be up when your users need it. The good news: the tools exist, the models are ready, and you can have a working fallback router deployed in an afternoon. The only thing missing is doing it before the next six-hour emergency.