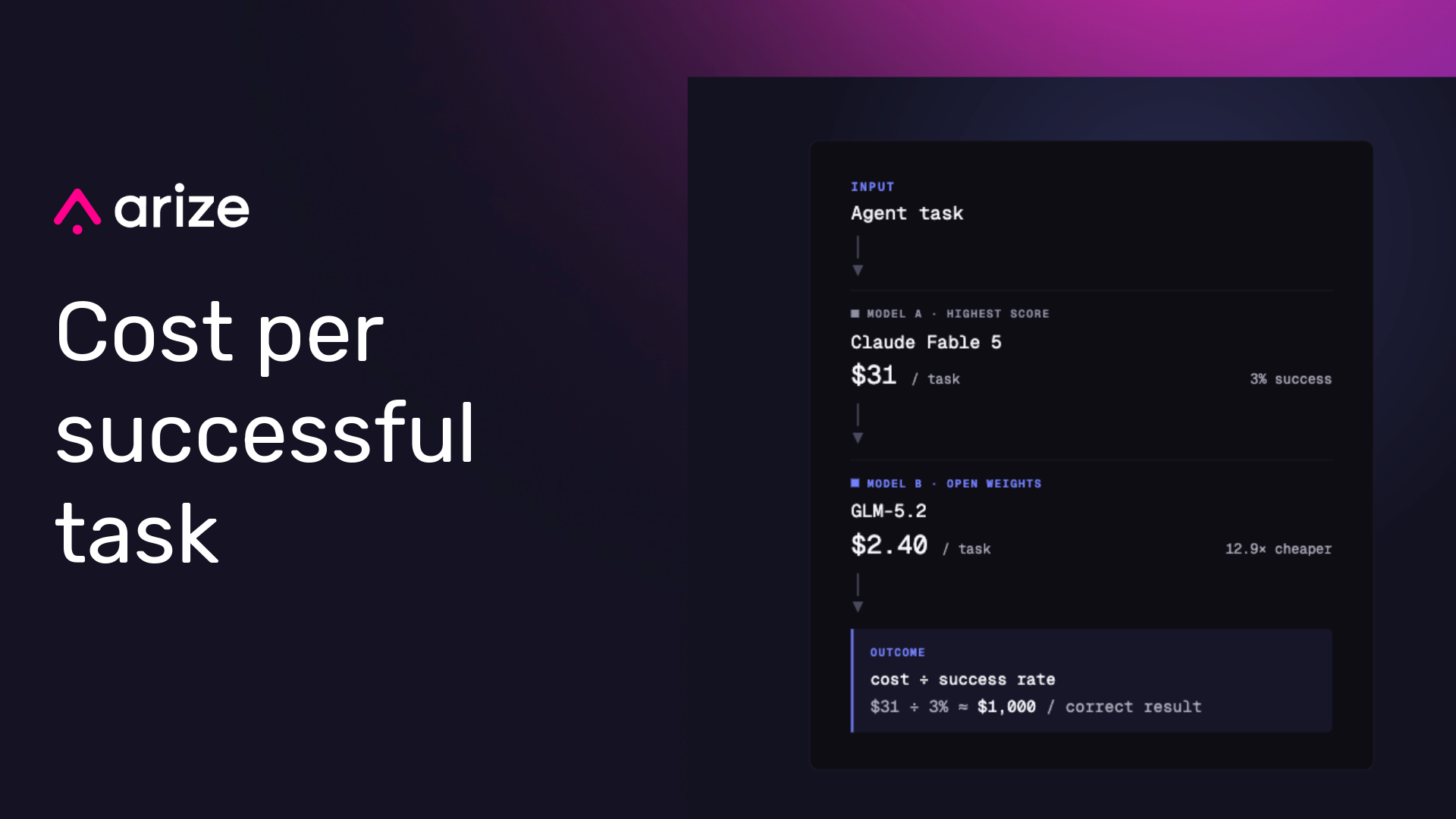
The smartest AI model ever released will complete one agentic knowledge-work task for about $31 in LLM inference cost, and it gets the whole task right 3% of the time, which works out to roughly $1,000 for a single fully-correct result. It turns out “smartest” and “most economical” are not the same model. But for the first time we can know which model is which.
The numbers come from AA-Briefcase, an agentic knowledge-work benchmark Artificial Analysis published on June 18. It is the first clean third-party measurement of what one unit of agentic work costs, on long-horizon tasks built by people who do this work at Google, McKinsey, and BCG. It arrives in the middle of an argument that has been going in circles for weeks. One side says the labs are losing billions and the whole industry runs on subsidy. The other says inference is high-margin and the labs are printing money. Both are right, because the labs have two different business models: flat-rate subscriptions, and token-based API pricing.
Both OpenAI and Anthropic have flat-rate plans, and the brutal economics of these plans say they have to stop, because agentic workloads have broken the model. If you build agents and run them on a $200 monthly plan, you’re the problem for the labs. The question is: when the subsidies end (and it’s when, not if) where do you go?
Flat-rate AI subscriptions are subsidizing agentic workloads
Nobody is hiding the data. SemiAnalysis bought every consumer tier and ran each to its weekly limit on long-horizon coding and agentic work, and the result is now widely quoted: a fully utilized $200 ChatGPT Pro plan, valued at published API rates, would cost up to $14,000 a month, a 70x gap. Measured against true serving cost, which SemiAnalysis puts near a quarter of list price, the same maxed-out user burns roughly $3,500 in compute against $200 in revenue, a 17.5x gap. This cost to the labs is concentrated on the heaviest users, making a flat plan a cross-subsidy: the person who asks three questions a day funds the engineer running agents overnight.
What ended that cross-subsidy as a viable business model is a change in the workload. A plan priced for chat is now running build-server work. Microsoft Research found agentic coding tasks consume roughly 1,000 times the tokens of a standard query, and the frontier models on AA-Briefcase spend over 100,000 output tokens on a single task.
One way out for the labs might be if costs per token dropped fast enough to escape their burn. And per-token cost is dropping fast, on the order of 9x to 900x per year depending on the capability. But total spend climbs anyway because agents consume orders of magnitude more tokens than the chat usage the plans were priced for. Agents are not straining the subscription model, they have dismantled it.
Why API-priced LLM inference has different economics
At the metered API layer the economics invert. We have some data on this too. According to leaked fiscal 2025 statements, reported by OpenAI critic Ed Zitron and independently verified by the Financial Times, OpenAI’s implied gross margins improved from 28% in 2024 to 43% in 2025 (the 43% figure includes subscription revenue, implying even better API-only margins). In March 2025, during its Open Source Week, DeepSeek disclosed a theoretical 545% cost-profit margin on its serving stack, with the caveat that real revenue runs lower because most usage is free or discounted. The 2026 echo came from the analyst scaling01, who argued that if GLM-5.2 sells at a profit at $4.40 per million output tokens while closed APIs charge multiples of that, the closed labs could run margins north of 90%.
So the two camps were never in conflict. Subscription economics and API economics are different businesses, and only one is subsidized. The flat plan loses money because of who uses it and how hard, not because a token is expensive to serve. The API pricing isn’t in any trouble.
Why AI agent pricing is moving from subscriptions to usage-based billing
It is inevitable because the capital behind it has a visible horizon. Epoch projects that aggregate cash capex across the major hyperscalers, growing about 70% a year, overtakes their operating cash flow, growing about 23% a year, around the third quarter of 2026, the point where combined free cash flow reaches zero. Past that line the buildout runs on outside capital, which will create pressure to cut costs or raise price.
The coming repricing will not hit every provider at once. SemiAnalysis’s utilization work shows OpenAI’s top tier reaching zero gross margin near 5.7% utilization against roughly 10% for Anthropic, so OpenAI is the most exposed and the likeliest to move first. Anthropic is not waiting. Its new metered credit caps for agent usage took effect on June 14. The all-you-can-eat plan is being repriced.
So we’re rapidly approaching a future when you have to pay the real cost of inference to run your agents. But as I’ve written before, you can’t do that math based on how much tokens cost. You have to do it based on what outcomes cost. And the last time I wrote about that, we didn’t have those numbers. Now we do.
How to calculate cost per successful task for AI agents
Cost per successful task is the cost of running a model on a task divided by the rate at which the model completes that task correctly. It is the number that matters for agentic workloads, because a cheaper model only saves money if it still produces the outcome you need.
AA-Briefcase ran frontier models against 91 private tasks across four multi-week projects and reported the cost of each directly.
Model | Cost per task | AA-Briefcase Elo | Cost vs GLM-5.2 | |---|---|---|---| | Claude Fable 5 | ~$31 | 1587 | 12.9x | | Claude Opus 4.8 (max) | $10.40 | 1356 | 4.3x |
| GLM-5.2 (max), open weights | $2.40 | 1266 | 1x | Cost per task varies by more than 800x across every model tested, from over $31 for the leader down to about $0.04 for a quantized DeepSeek variant that never reaches frontier quality. But the number that matters even more is the success rate. Fable 5 leads the benchmark and satisfies every rubric criterion on 3% of tasks, and on 31 of the 91 tasks no model scores above 50%. So the real cost per outcome is cost per successful task, cost divided by the rate the work is done right, and for Fable that is about $1,000 for one fully-correct result in this benchmark.
But in the AA-Briefcase benchmark, the only model with meaningful successful outcomes was Fable. To figure out your own cost per successful task, you need to run evals on your own workloads. Arize AX helps teams trace agent runs, evaluate success, and compare model changes by outcome cost.
Use evals to switch to cheaper AI models without losing quality
The table above shows you the decision you haven’t made yet. Artificial Analysis names open-weight GLM-5.2 and DeepSeek V4 Pro as the strongest price/performance options on the board, with GLM-5.2 landing about 90 Elo below Opus 4.8 for less than a quarter of the cost and outranking GPT-5.5 xhigh while costing less to run. On a metered bill, paying 4.3x for Opus or 12.9x for Fable 5 over GLM-5.2 is a choice you would have to justify per task. On a flat plan you never see it, so you never make it.
That is what flat rate plans have been buying you: the freedom to ignore price-performance tables and run whatever model scores highest. The day the meter turns on, the 4.3x and the 12.9x stop being invisible and start being actual bills, and cost per successful task will dictate your new stack.
The rational move is the one the benchmark already points to: down the capability curve to the efficient open-weight models, and onto backends you can fine-tune and self-host. Open weights keep collapsing in price, with DeepSeek V4-Pro at $0.435 in and $0.87 out per million tokens, and teams are already cutting real workloads on them, as Decagon did to take voice-agent cost down roughly 6x.
The hard part is not finding a cheaper model. It is switching to one without losing the success rate that justified the expensive model in the first place. That is an evaluation problem before it is a cost problem, and it is the one worth solving now, while you can still A/B a downgrade against a subsidized baseline. We wrote the playbook for exactly this move: how to ditch your frontier model for an SLM.
What to do before AI model subsidies end
Subsidies are ending, you are the party being subsidized, and the meter is coming. So run the expensive models while choosing the best result is still free, and build as though the meter is already on. Know your cost per successful task, keep your workloads portable enough to move down the curve, and validate the switch with evals before the bill forces it. The cheapest your agent will ever be to run is today. Spend that head start on getting ready.