LLM-style scaling laws hold for sensor data #
Much of the magic of LLMs comes from the fact loss scales predictably with model size, dataset size, the amount of compute used for training. It’s easy to take scaling laws for granted, but they only published in 2020 and their structure underlies both the economics of AI (if not for scaling laws, frontier labs couldn’t invest nine figures in a training run) and AI’s emergent capabilities (the Phillip Anderson quote, “more is different”, comes to mind).
Do similar scaling laws apply to non-language foundation models, such as wearable foundation models? It turns out they do. Is the form exactly the same? It is not, which leads to some interesting questions.
First, let me describe an example of a non-LLM scaling law.
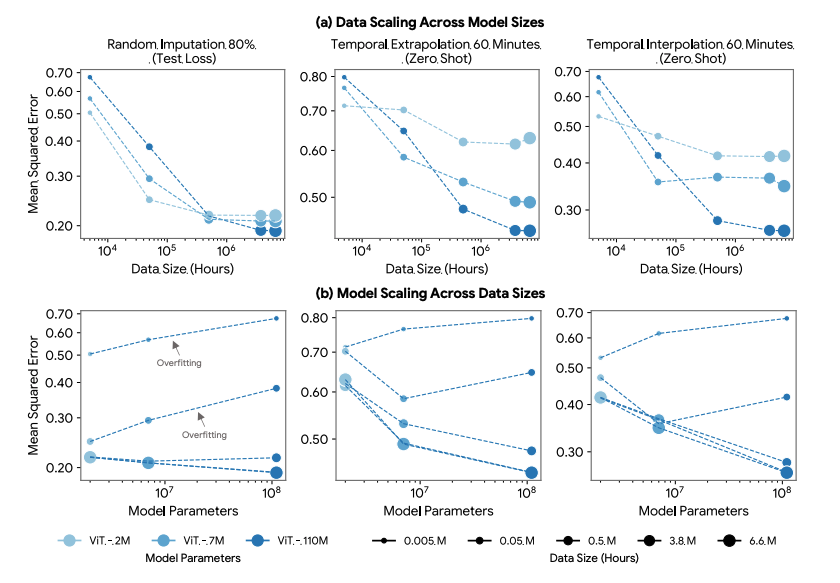
A non-LLM scaling law Google’s Scaling Wearable Foundation Models was, to my knowledge, the first paper to establish a scaling law for physioloigical sensor data from wearables: Scaling performance of a wearable foundation model as a function of data size & model size. Source: Scaling wearable foundation models.
Validation loss scaled as:
where is compute, is the power-law exponent, and is an irreducible floor (more on that later). Across multiple orders of magnitude, loss falls along a nearly straight line on the log-log plot before bending toward the floor (the same shape holds when you vary data hours or parameters instead of compute). LSM tested four model sizes (2M, 7M, 110M, and 328M parameters) against data from a few thousand hours up to 40 million. Bigger models and more data both helped on every generative task they measured: random imputation, temporal interpolation, sensor imputation, and forecasting. The payoff on downstream, post-trained tasks was good too. Fine-tuned LSM improved interpolation and forecasting by 16-23% over baselines and lifted activity recognition by 29%.
Non-LLM scaling laws are similar, but not identical to LLM scaling laws LLM scaling laws were first established in Kaplan et al. (2020), and then refined in the 2022 Chincilla paper. In the Chinchilla scaling laws, for a fixed compute budget, you should scale parameters and tokens together, about 20 tokens per parameter. Chinchilla was a 70B model trained on 1.4 trillion tokens, and it beat models several times its size that had been starved of data.
The Chinchilla LLM scaling laws are expressed as:
Here, is the validation loss; represents the irreducible loss floor; and , , , and are fitted constants (exponents and multipliers). One widely cited finding is that, under a fixed compute budget, optimal results are achieved by scaling data and model size together: specifically, the compute-optimal regime is where the number of training tokens is proportional to the number of parameters (in practice, about 20 tokens per parameter).
One major difference is that LSM’s gains flattened out around 10 million hours of data and roughly 100 million parameters. LLMs have shown no such ceiling at consumer scale. Chinchilla used 1.4 trillion tokens and frontier models have gone well past that, with no flattening yet. (Both scaling laws have an irreducible error term, so this isn’t a difference in functional form but rather an empirical result.)
That’s a potentially interesting opportunity for startups. We trained a JEPA-style wearable foundation model, JETS, on the same order of magnitude of data as Google and Apple with a four-person team. So whereas starting another LLM foundation model company requires billions of dollars of investment, non-LLM domains might actually be open for smaller startups.
[Some open questions I have](#some-open-questions-i-have)
While the power laws rhyme, many of the underlying details are pretty different:
| Dimension | LLM scaling | Wearable sensor scaling |
|---|---|---|
| Unit of data | Tokens (discrete vocabulary) | Hours of continuous, multi-channel signal |
| Pretraining objective | Next-token prediction | Masked reconstruction (80% of patches hidden, MSE loss) |
| Loss | Cross-entropy / perplexity | Mean squared error on held-out patches |
| Saturation | None yet at trillions of tokens | Flattens near 10⁷ hours and ~10⁸ parameters |
| Compute-optimal recipe | ~20 tokens per parameter (Chinchilla) | Scale data and model together; total hours dominate |
| Data supply | Finite; the public text pool is being exhausted | Renewable; billions of devices generate hours continuously |
| Economics | Oligopoly with $1B+ entry cost | Capital light? |
This leads to several interesting questions:
Data wall. LLMs are running into a data wall, where the stock of high-quality public text is close to spent and synthetic data is an uneasy substitute. As Ilya Sutskevar put it in his talk on the end of pretraining, “we have but one internet.” Physiological data has the opposite problem. Every watch on every wrist generates roughly 8,760 hours of new signal a year, passively, forever. The binding constraints for sensor models are labeled outcomes, compute, and the messiness of real-world data. If we can find architectures that reduce c to 0, there’s actually a very high ceiling on these laws.Market structure. T Rowe Price put it, “the economic rationale for AI capital expenditure ultimately rests on scaling laws.” Marginal compute must lead to marginal performance, which is why frontier labs are essentially an oligopoly with an entry price of $1B+. If the scaling laws are different, does this mean the compeitive dynamics are different?Same or different latent space? We’ve seen interesting implications from aligning vision models into the LLM’s latent space (e.g., CLIP). Will there ultimately be one latent space for all models? Or will we see physiological and other models have their own latent spaces that make meaningful distinctions that are too subtle to fit in language?
Get your free 30-day heart health guide #
Evidence-based steps to optimize your heart health.