How hiring is becoming a luck filter.
This open-source ATS by HackerRank has been blowing up recently: https://github.com/interviewstreet/hiring-agent
It’s popped up on LinkedIn and Reddit with hundreds, sometimes thousands, of likes.1 A coworker mentioned it to me in passing a few days ago.
I’ve decided to test it out.
First working run: 90/100. Felt pretty good!
I had some debug prints scattered around from troubleshooting the setup, so I cleaned those up and ran it again.
74/100.
Same resume. Same command. The only thing I changed was deleting print statements.
I disabled DEVELOPMENT_MODE
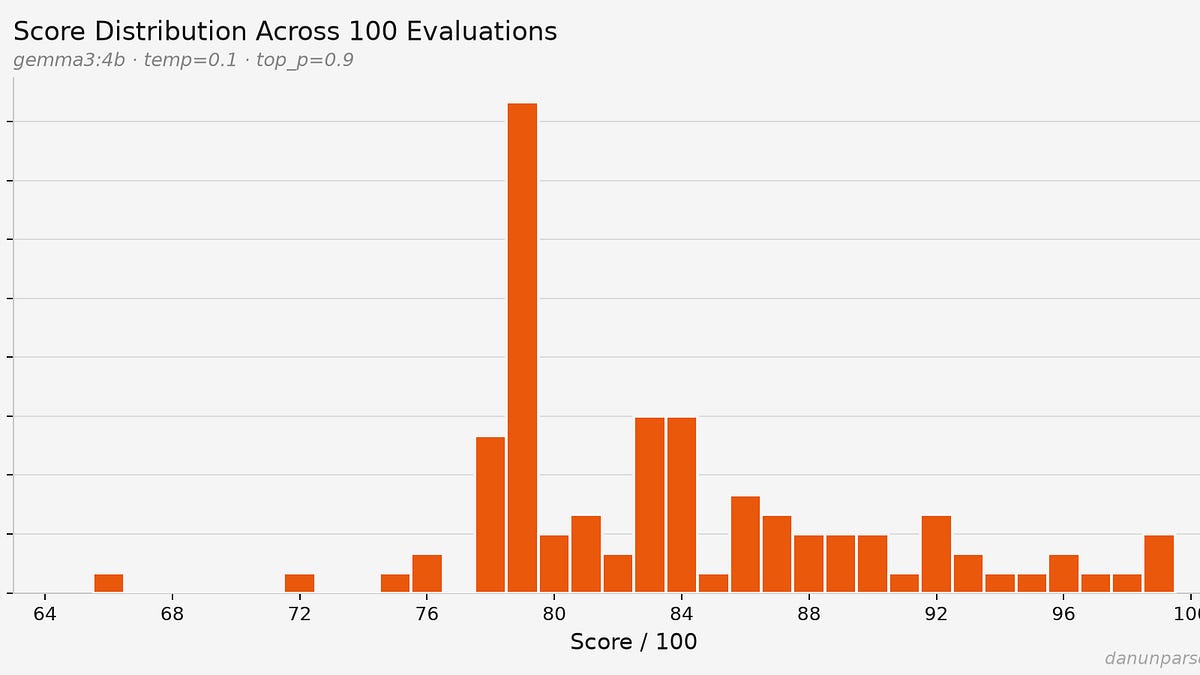
and put it in a loop to run a hundred times.
The scores range from 66 to 99.
If your company’s cutoff sits at 85, I fail 65% of the time. Same exact resume, different luck.
Here a quick rundown on how the tool works:
Your PDF gets parsed into text. An LLM is called six times to extract structured information — your basics, work history, education, skills, projects, awards. It pulls your GitHub profile, scans your top repos, appends them as extra context. Then everything gets fed into the LLM at once to be graded.
The scoring is out of 100, with up to 20 bonus points on top:
35 points for open source contributions
30 for personal projects
25 for work experience
10 for technical skills
Up to 20 bonus points for startup experience, a portfolio site, a technical blog, etc.
The default model is gemma3:4b, running at temperature 0.1 — low, supposedly nudging the model toward deterministic outputs.
Here’s what I found when I looked at those individual categories.
Look at technical skills: I scored 8/10 in 98 out of 100 runs. Nearly perfect consistency. How come? Because technical skills are a checklist. You either know React or you don’t. There’s nothing for an LLM to judge — a five year old could match that check-list.
Now look at projects — there’s HUGE variation.
LLMs struggle to make a judgment call like that consistently. Sometimes my projects “lack architectural complexity”, sometimes they “demonstrate real-world deployment”. Which one the LLM spits out is a roll of the dice.
Temperature 0.1 is already low, but even going down to temperature 0 doesn’t fix this. Someone opened a GitHub issue back in October showing scores of 27, 34, 32, 34, 34, 30 across six consecutive runs at temperature 0.2 This non-determinism isn’t a bug you can just fine-tune away, it’s a fundamental design flaw.
I was worried part of this might be the model. After all, gemma3:4b was a local model running on my machine.
Gemini resulted in a tighter distribution — scores clustered between 48 and 64. But if your cutoff is 60, you’re still failing 28% of the time through no fault of your own.
The Open Source scores have become consistent — that’s a legit improvement. But project scores are still all over the place.
Experience has me the most concerned.
25/25.
Every single run.
I went back and pulled up an old resume — one internship on it.
Also 25/25.
The clue is in the prompt…
### Production (0-25 points)
- Analyze the 'work' and 'volunteer' sections for real-world, internship, or production experience
- **SPECIAL CONSIDERATION**: Give extra points for founder roles, co-founder positions, or early-stage engineer roles (first 10-20 employees) at startups
The entire thing is two lines long.
No rubric. No examples. No anchors for what earns a 15 versus a 25.
A junior engineer with one internship gets 25/25. A principal engineer with a decade of distributed systems gets 25/25. I get 25/25. Experience has two lines and no anchors — consistent, but useless. Projects has a detailed rubric with examples but it’s the noisiest category — inconsistent, also useless. There are some things that LLMs just can’t do well, no matter how you prompt.
Use an LLM to parse a resume into structured data — great, that’s what they’re good at. Use one to check whether someone knows Python — amazing. Use one to judge whether a candidate’s experience is worth 18 points or 24 points? You get a vibe-check. Something HR teams, bar raisers, and a dozen other initiatives have spent decades trying to avoid.
The 65% weighting on open source + projects doesn’t help either. I’d take the engineer with 30 years of experience who built S3 over someone with two internships and an open source project — but this tool wouldn’t. Some of the best engineers I know have built things that never ended up on GitHub. That’s over half of their score gone before any human looks their way.
If you’re an engineer with any say in how your company handles resume screening: please be very careful with AI-screening tools. A tool that can’t differentiate isn’t filtering for quality — it’s just filtering. You might as well throw out half the resumes and tell the the applicants you don’t fuck with bad luck.
Correction (June 28): A reader flagged that the resume_evaluation_criteria.jinja template says “Software Intern” on line 1 — nowhere documented, nowhere else referenced in the repo. The same template that later gives bonus points for “founder roles, co-founder positions, or early-stage engineer roles.” I re-ran with an explicit Senior SWE prompt and got identical results — the scoring dimensions are position-agnostic.
Non-determinism at temperature 0 was flagged in this GitHub issue, opened October 2025.