I do not think the next step for coding agents is stuffing more of the repository into the prompt. The hard problem is not how much context a model can carry. It is whether the agent has a durable, believable memory of the codebase and the team changing it.
Large context windows are useful. I use them. They let a model hold more files, more logs, more discussion, and more intermediate state before it has to summarize or forget. But for coding agents, context size is often mistaken for continuity.
Continuity is different. Continuity means the system knows what happened before this prompt. It knows which findings were real, which ones were dismissed, which conventions the team corrected, which files tend to move together, which dead ends should not be explored again, and which assumptions have already been proven wrong.
A larger window can carry more text. It does not decide what is worth remembering. It does not know what to trust. It does not turn a correction from last week into a constraint on today's review.
Context is not memory. #
Most coding agents are context-native or tool-native. A context-native agent works by packing the right files into the prompt. A tool-native agent can search, grep, inspect symbols, and call external systems. Both are important, but both still tend to treat every task like a fresh investigation.
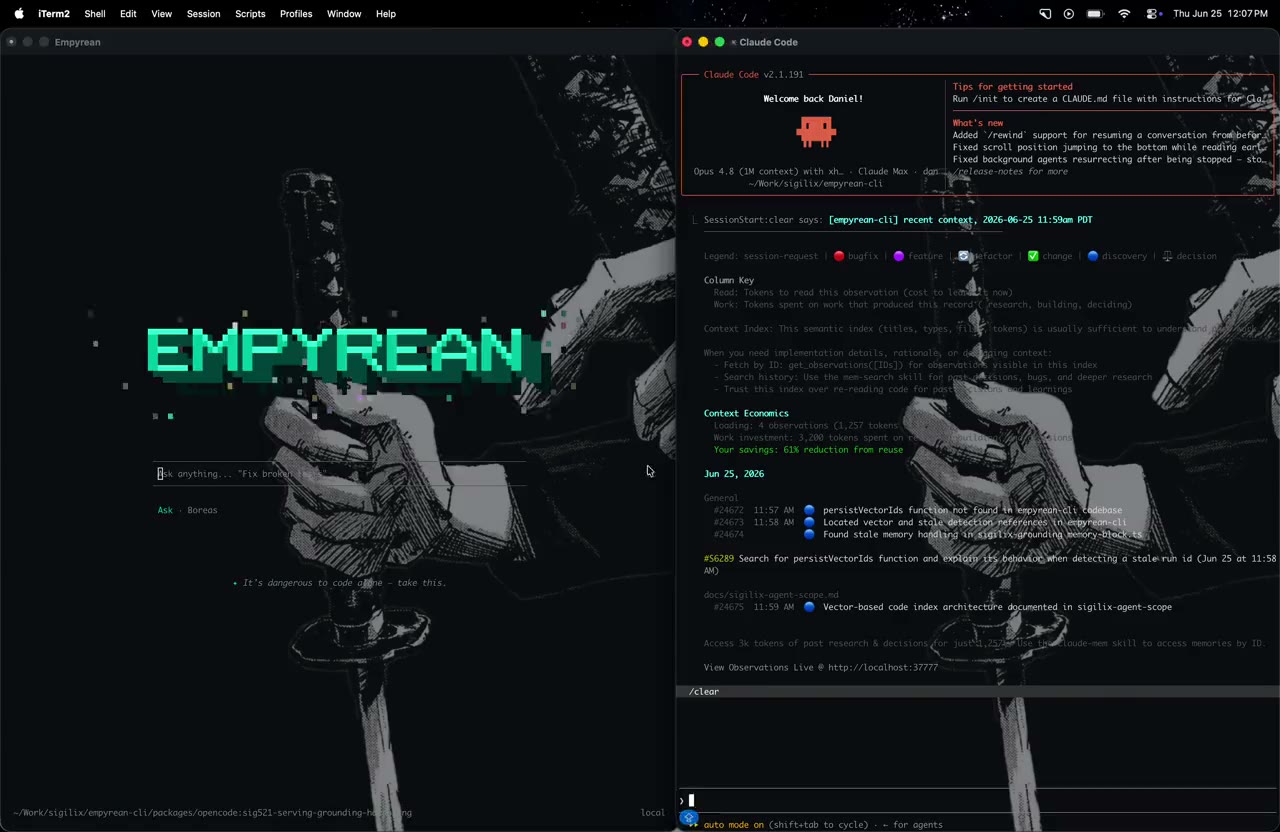
Sigilix is pushing toward a different shape: memory-native coding agents. In that model, the agent does not merely fetch context when asked. It works against a persistent repo backing layer that is updated by reviews, dismissals, comments, fixes, issue triage, and agent sessions. Every interaction can leave behind evidence that future interactions can use.
That does not mean keeping everything forever. Most interaction data is noise after a few days. The useful parts are decisions, corrections, task state, conventions, dependency relationships, and proof. The memory layer has to be selective, or it becomes another pile of context to drown in.
Retrieval is not enough either. #
The obvious objection is that good retrieval should solve this. Index the repo, build a graph, find the relevant files, and put them in front of the model. That is a real improvement over pasting a diff into a chat window. It is also not the same thing as memory.
Retrieval answers the question: what text might be relevant right now? Memory answers a different question: what has this repo already taught us that should constrain the answer? Those are not interchangeable. A search result can show the model the current implementation. It will not, by itself, tell the model that this team already rejected a proposed pattern three reviews ago, or that a finding which looks suspicious was previously proven to be a false positive, or that a weird local convention exists because production depends on it.
This is why a coding agent can have great retrieval and still feel forgetful. It can find the right file and still ask the same question again. It can read the same helper and still propose the same wrong abstraction. It can inspect the same diff and still fail to carry forward the human correction that made the last review useful.
The loop changes when memory is native. #
In a context-first loop, the agent starts with the prompt, gathers files, reasons, and emits an answer. If the answer is wrong, the user corrects it. In many products, that correction is just part of the chat history. It might survive for the session. It might be summarized. It usually does not become a durable constraint on the next agent run.
In a memory-native loop, the correction is not just conversation. It is a signal. A dismissal, an accepted fix, a review reply, a merged PR, a triaged issue, and a failed hypothesis can all update the backing layer. The next time an agent touches the same surface, it should not begin from zero. It should inherit the repo's learned shape: what matters, what was already checked, what the team prefers, and which claims need proof before anyone should believe them.
That changes the model's job. The model is still reasoning, but it is no longer responsible for reconstructing all of the institutional memory from raw text every time. It can spend its capacity on the current problem because the system around it is carrying the durable parts.
Memory access is not memory competence. #
The distinction became clear while I was testing Boreas, the first model in our Empyrean line. Boreas is not a frontier model. Without the Sigilix backing layer, it is not impressive. The interesting result only appears when the model is designed to work through memory instead of treating memory as one more tool call.
In this run, both sides had access to the same repository and the same memory-backed context. The larger model could see the substrate. It just did not know how to live inside it. It kept reasoning itself into uncertainty, checking and rechecking what it should trust.
This is the part I think is easy to miss from the outside. Giving a model access to memory does not automatically make it use memory well. A general model can treat the backing layer as another pile of observations to debate. It can spend its budget deciding whether the memory is relevant, whether a name mismatch means the memory is stale, whether the repo has another equivalent path, and whether it should trust the index at all. That caution is not irrational. It is just expensive, and in a coding agent it can become the whole task.
Boreas did something less dramatic and more useful. It fetched the codebase graph, grounded the task in the prior repo state, and answered directly. That is the point. I am not claiming Boreas is globally better than Opus. It is not. I am claiming that a model shaped around persistent memory can beat a stronger general model on continuity-heavy coding tasks.
The failure mode looked less like hallucination and more like over-deliberation. The stronger model kept trying to prove the ground under its feet. The smaller model, because it was tuned to work through the substrate, used the substrate and moved on. That is the design lesson I care about.
What should actually persist? #
The naive version of memory is a transcript. Save every prompt, every answer, every file, every review, every Slack thread, and hope retrieval sorts it out later. That is just a bigger context window with worse ergonomics.
The useful version is closer to an engineering ledger. It stores facts that future work can safely lean on:
- Decisions: why the team chose one pattern over another.
- Corrections: what the system got wrong, and what the human accepted instead.
- Dead ends: checks that were already tried and proven irrelevant.
- Conventions:the repo's real local rules, not generic style advice.
- Task state: what is already done, what is blocked, and what must be verified next.
- Evidence: the proof that made a finding believable in the first place.
The model should not have to be huge. #
The expensive pattern today is to ask a frontier model to rebuild the world on every task. It opens files, infers conventions, re-derives call paths, checks history, decides what matters, and then finally starts coding or reviewing. A bigger window makes that possible for longer, but it also encourages the system to carry too much raw material at once.
A memory-native agent changes the budget. The model still spends tokens, but it does not have to rediscover the repo every time. The backing layer supplies the graph, the trust record, the relevant decisions, and the useful prior failures. The model's job narrows to reasoning over a prepared substrate.
That is why a smaller model can become surprisingly capable in this setup. It is not because the smaller model secretly became a frontier model. It is because the task stopped asking the model to be the database, the search engine, the memory system, the judge, and the executor all at once.
Memory can also make agents worse. #
A memory-native system has sharper failure modes than a stateless chat model. If memory is stale, the agent can confidently apply an old rule to a changed code path. If memory is too eager, the agent can overfit to a team preference that was local to one feature. If memory has no proof discipline, the system can turn a past hallucination into future infrastructure.
That is why I keep using the word believable. Memory only helps if the system records where a claim came from and why it should be trusted. A remembered convention should have examples. A remembered dismissal should know what was dismissed and under what condition. A remembered finding should carry the evidence that made it real. Without that, memory becomes folklore with an API.
There also has to be decay. Some facts should disappear. Some should be demoted. Some should be overwritten by newer decisions. The goal is not a perfect archive. The goal is a working memory that keeps the durable parts of engineering judgment while letting stale observations fall away.
What I am not claiming. #
I am not claiming context windows do not matter. They do. I am not claiming Sigilix has solved general intelligence. It has not. I am not claiming Boreas is better than the frontier models on open-ended reasoning. It is not.
The narrower claim is the one I care about: coding agents need a persistent, believable backing layer more than they need another order of magnitude of prompt space. When the work is tied to a living repository, the agent has to remember the repository as a changing system, not as a document dump.
I also do not think this eliminates the need for strong models. There are tasks where frontier reasoning is the right tool. The mistake is asking the frontier model to compensate for missing product architecture. A better model helps. A better memory substrate changes the task the model is being asked to perform.
Where this goes. #
If every PR, review, dismissal, issue, and agent session improves the backing layer, the repo starts to develop continuity. The first review is just a review. The hundredth review is also a training signal for how the team actually works. That is the product thesis behind Sigilix. Code and AI are now intertwined, but the winning abstraction is not an infinite prompt. It is a coding system that can remember what happened, decide what remains believable, and give even modest models the substrate they need to act like useful teammates.
That is also why I think this matters economically. If the only path to useful coding agents is buying larger and larger context windows from frontier models, the tool gets better but the cost curve stays painful. If the product can move durable knowledge out of the prompt and into the architecture, smaller models get more useful, larger models waste less work, and teams stop paying to rediscover their own codebase every session.
One sentence version.
Bigger context windows help a model carry more text; memory native architecture helps an agent carry forward what a team has already learned.