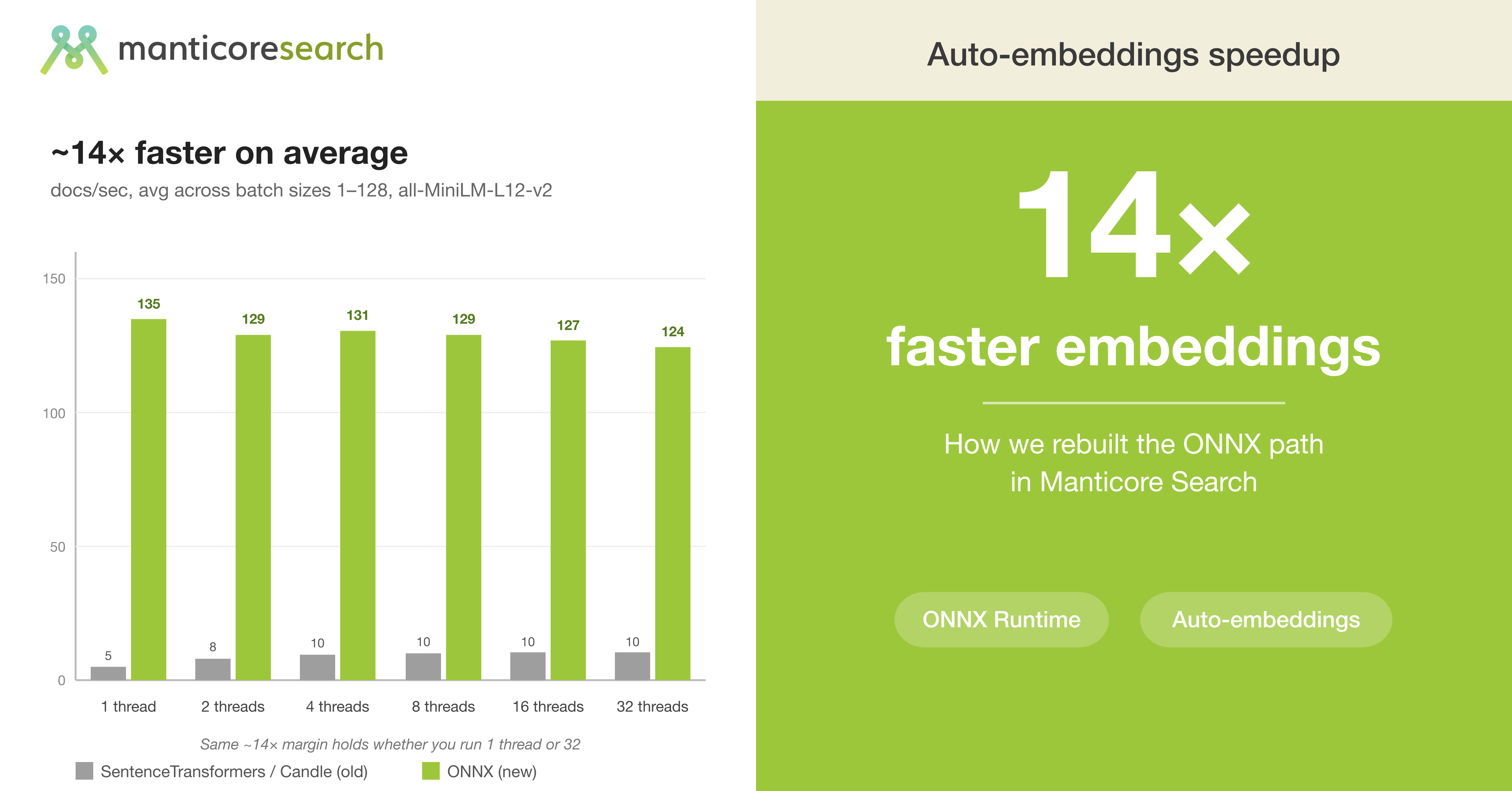
When we shipped Auto Embeddings — the feature that turns any text column into a vector automatically, with no separate model service to run — the most common piece of feedback was about speed. The previous path went through SentenceTransformers on top of Candle , Hugging Face's pure-Rust ML inference runtime, and it left a lot of CPU on the floor: most workloads sat in the low-double-digits of docs/sec no matter how we fed them, and concurrent calls serialised on a single model session.
So we spent a few weeks rebuilding how Manticore runs ONNX models. The new ONNX Runtime backend shipped in Manticore Search 27.1.5
. ONNX (Open Neural Network Exchange) is the portable model format that most of the popular open-source embedding models — MiniLM, BGE, E5, and friends — already publish. The result is a backend that's ~14× faster on average than the previous SentenceTransformers/Candle path on the same hardware (average cheap 16 cores / 32 threads server), same model, same weights, averaged over the full threads × batch
workload grid — and that advantage holds whether you run 1 client thread or 32. The old path stayed in the 5–11 docs/sec range across the entire grid; the new one lives in the 70–230 docs/sec band.
This post is the engineering log: what we tried, what surprised us, what we threw away, and what the final design looks like.
TL;DR #
~14× faster on average than the previous SentenceTransformers/Candle path, averaged across the fullthreads × batch
workload grid (1 / 2 / 4 / 8 / 16 / 32 threads × batch sizes 1…128) on the same box (16 cores / 32 threads), same model, same weights.- Released in
Manticore Search 27.1.5, the new ONNX path is now the default fast path for any HuggingFace model that ships an.onnx
file. - On
all-MiniLM-L12-v2
, the old Candle path sat at5–11 docs/sec across every configuration we tried. The new ONNX path lands in the70–230 docs/sec range — thesame ~14× margin holds whether you run 1 client thread or 32. - Single-insert latency on our test box:
~14 ms with a single client,~56 ms under 8-way concurrent load — both well below the 200+ ms Candle was hitting. Want maximum bulk ingest throughput? Use ahigh batch size(32–128) on a** single client thread**. The new backend parallelises inside the call, so client-side fan-out just piles coordination overhead on top — peak on our box was233 docs/sec at 1 thread + batch=64.- The two changes that mattered most: turning
, and giving up on batching documents inside the worker.intra_op_spinning
off - No user-facing API changes. A table that already points at an ONNX-capable
MODEL_NAME
picks up the new path automatically. Switching an existing table to a different model isn't a one-liner — Manticore doesn't allow alteringMODEL_NAME
on aFLOAT_VECTOR
field in place — but you don't have to recreate the whole table either: you can add a new column with the new model alongside, rebuild its embeddings, and drop the old one.
Why this matters #
With auto-embeddings, the database itself runs the model on every INSERT
. That means embedding speed is INSERT speed — your ingest throughput is whatever the embedding step can sustain.
The old SentenceTransformers/Candle path left performance on the table. Concurrency hit lock contention, batched calls plateaued because of padding overhead, and between calls the runtime parked threads in ways that prevented the next call from picking up where the previous one left off. The headline symptom was simple: top
would show the box well under full load no matter what you threw at it. The whole sweep — single-row INSERTs, 128-row bulk INSERTs, one client thread, thirty-two client threads — sat at 5–11 docs/sec, because nothing about how you fed it could buy you more CPU.
The new ONNX path raises the floor by an order of magnitude and gives users meaningful performance tuning options. A single-thread, single-row INSERT now lands 72 docs/sec — already ~7× the old Candle ceiling. Add concurrency or batch size and it climbs into the 130–230 docs/sec range, with the top of the grid at 233 docs/sec on a single client thread at --batch-size=64. Averaged across the whole
threads × batch
matrix, the new path is ~14× the old one.
Why ONNX, and not Candle #
Manticore's embeddings library has supported a few backends for a while. The Candle path is great for correctness and easy to ship. But for production inference of small encoder models like the MiniLM and BGE family, ONNX Runtime is hard to beat:
- ONNX Runtime (or
ORT— Microsoft's official, hand-tuned C++ inference engine for ONNX models) does graph fusion, constant folding, kernel autotuning. - Most of the popular embedding models on HuggingFace already publish a pre-fused
model.onnx
in theironnx/
directory. The on-disk file is already in the shape ORT wants.
On the same all-MiniLM-L12-v2
weights, on CPU, the ONNX path is a noticeable step up over the Candle path. Same quality, much less per-document work.
The ORT session is created with a small set of opinions:
let session = ort::session::Session::builder()?
.with_optimization_level(GraphOptimizationLevel::Level3)?
.with_intra_threads(0)? // let ORT pick (= all cores)
.with_intra_op_spinning(false)? // do NOT busy-wait between calls
.with_flush_to_zero()? // kill denormals on attention softmax
.with_approximate_gelu()? // ~10% faster activation, no quality loss
.commit_from_file(&onnx_path)?;
Most of these are uncontroversial, "of course you turn that on" knobs. One is not: intra_op_spinning(false)
. We'll come back to it — it's the single biggest win in the whole branch, and it's not really an ORT setting so much as a load-shape decision.
The concurrency model — the part most readers will find new #
If you give a Rust developer "make ONNX go fast" with no other constraints, they reach for one of two patterns. We tried both. They are both wrong for this workload.
Pattern 1: a single shared Session behind a Mutex (a
Mutex
is a lock that lets only one thread touch the session at a time). Easy to reason about, easy to get right. Throughput collapses under concurrency because every caller serialises on the lock. Fine for a CLI tool, awful for a database serving many concurrent INSERTs.Pattern 2: a session pool, one Session per CPU. No more lock contention, but cold-start time multiplies, RAM use multiplies, and small inputs pay a dispatch cost just to land on a session. We had a working version of this in a development branch and it never quite delivered.
The thing that unlocked the design is something most Rust ONNX wrappers get wrong: on Linux and macOS, ORT's C Run() API is thread-safe. You can share one
Session
across many concurrent callers without any locking. The C++ side already serialises what needs serialising; the Rust API just hides it behind borrow-checker rules that do not match what the underlying library actually allows.So we wrap the session in a small platform-aware type:
#[cfg(not(target_os = "windows"))]
struct SessionWrapper {
inner: std::cell::UnsafeCell<ort::session::Session>,
}
#[cfg(not(target_os = "windows"))]
unsafe impl Sync for SessionWrapper {}
#[cfg(not(target_os = "windows"))]
unsafe impl Send for SessionWrapper {}
impl SessionWrapper {
fn with_session<R>(&self, f: impl FnOnce(&mut Session) -> R) -> R {
f(unsafe { &mut *self.inner.get() })
}
}
Yes, this is unsafe
. We're taking the borrow checker out of the loop because the underlying library is documented to be safe under the access pattern we're using. It's a deliberate unsafe
with a one-line justification, not a foot-gun.
On Windows, ORT's threading model has known issues, so we serialise Run()
with a Mutex
. Importantly, the lock is held for the entire closure, not just the call to run()
— that's what fixed the race we saw on Windows where one thread's SessionOutputs
were still being read while another thread had already started a new run()
. Closure-scoped locking, not call-scoped.
Adaptive parallelism — the wrong turns we took #
This is the part of the work that took the longest, because every textbook says "to make ONNX fast, batch your inputs". So our first attempts followed the textbook.
We tokenized chunks of 8, 16, 32 documents at a time, padded them to max_len
, and ran a single forward pass per worker thread. The throughput numbers came back lower than processing the same texts one-by-one through the same session. We ran it again. Same result. We spent a while trying to disprove it before accepting it. The reverted commit 980b24b "Revert: perf(model): batch inference in worker threads"
is the moment we stopped fighting and rebuilt around what the profiler kept telling us.
Two things were behind the surprise.
The padding tax. A batch of mixed-length texts pads every row up to the longest row. The model then does work proportional to batch_size * max_len * hidden_dim
, regardless of how much real content is in the batch. Real text inputs are highly variable in length: a typical batch of 8 random sentences might have one 60-token outlier and seven 8-token rows. The model spends most of its cycles multiplying padding tokens against attention weights. With one-doc batches, the model only does work proportional to that doc's actual token count. Per-document, "no batching" is cheaper than "batching" once the variance in input length is realistic.
Spinning. ORT's intra-op thread pool defaults to spinning between dispatches — threads burn CPU in a tight loop waiting for the next chunk of work. With one big batch per session call this is invisible: the thread is always busy with real work. With many concurrent small calls, it becomes a disaster: every worker's intra-op pool is pinned at 100% CPU between calls, and there's no CPU left for anything else. We saw exactly this pattern in top
: every core at 100%, throughput lower than spinning-off. This sounds wrong until you remember the rest of the system needs CPU time too — the tokenizer, the HNSW build, the rest of searchd
. Flipping with_intra_op_spinning(false)
on was a one-line change that immediately raised throughput and dropped CPU usage at the same time.
So the final shape is the opposite of the textbook recipe:
One shared session, no pool.** One document per inference call**, no batching inside the worker.** Many concurrent callers**, scaled to CPU count.** No spinning**between calls — yield the CPU like a polite citizen.
fn predict_pipelined(&self, texts: &[&str]) -> Result<Vec<Vec<f32>>, _> {
let bs = batch_size();
// Small input — single tokenize + infer, no thread overhead.
// This is the path a 1-doc INSERT takes.
if texts.len() <= bs {
return Self::tokenize_and_infer(&self.session, &self.tokenizer, texts, ...);
}
// Large input — split across workers, each running 1-doc-at-a-time
// through the SHARED session. This deliberately mimics the
// many-concurrent-callers pattern that ORT is happiest with.
let num_workers = (texts.len() / bs).min(available_cpus()).max(1);
let docs_per_worker = texts.len().div_ceil(num_workers);
std::thread::scope(|s| {
for worker_texts in texts.chunks(docs_per_worker) {
s.spawn(move || {
for text in worker_texts {
Self::tokenize_and_infer(&session, &tokenizer,
std::slice::from_ref(text), ...)?;
}
Ok(())
});
}
});
// ...
}
The two-branch design is on purpose. A 1-row INSERT comes in with texts.len() == 1
, which is <= bs
, so it takes the fast path with zero thread spawning, zero channel sends, zero coordination overhead. A bulk REPLACE INTO with thousands of rows takes the parallel branch and gets the throughput benefit. The cheap case stays cheap, the expensive case stays parallel.
We also enable parallel tokenization once at startup (TOKENIZERS_PARALLELISM=true
) and pre-truncate inputs by character count before BPE, so a 100KB blob of text doesn't pin a CPU on the tokenizer for a second before the model even sees it.
Numbers #
All runs on our standard benchmark box, using all-MiniLM-L12-v2-onnx
, 1000 documents per run. Generated with manticore-load :
manticore-load --quiet --drop --batch-size=1 --threads=8 --total=1000 \
--init="CREATE TABLE t (
f text,
v FLOAT_VECTOR KNN_TYPE='hnsw' HNSW_SIMILARITY='l2'
MODEL_NAME='onnx-models/all-MiniLM-L12-v2-onnx' FROM=''
)" \
--load="INSERT INTO t(f) VALUES('<text/10/100>')"
Same command with --batch-size=2
, 8
, 32
, 128
, all at 8 threads:
--batch-size |
docs/sec | avg call latency (ms) | per-doc latency (ms) |
|---|---|---|---|
| 1 | 143 | 55.9 | 55.9 |
| 2 | 113 | 141.6 | 70.8 |
| 8 | 91 | 703.3 | 87.9 |
| 32 | 146 | 1753.4 | 54.8 |
| 128 | 147 | 6966.0 | 54.4 |
Compared against Candle at the same 8 threads — which sat flat at 10 docs/sec across every batch size — that's between 9× and 15× more documents per second depending on the batch you pick. The "avg call latency" column is the time for one full INSERT
statement to return, not per document; divide by the batch size and the per-doc cost lands in the 55–90 ms band.
If you swap the table to 1 client thread — the configuration that turns out to be optimal for bulk — the numbers climb further: 72 / 76 / 93 / 175 / 233 / 222 docs/sec at batches 1 / 2 / 8 / 32 / 64 / 128. The peak in the entire grid is 233 docs/sec at 1 thread × batch=64, with per-document latency of ~4.3 ms.
How to feed it for maximum throughput
If you're a lot of data in bulk and want maximum docs/sec, the recipe is straightforward: send large INSERT ... VALUES (..), (..), ...
statements (batch 32–128) from a single client thread, not many small inserts from many threads. The new backend already parallelises inside the call (see the predict_pipelined
code above), so client-side fan-out just piles coordination overhead on top of what ORT is already doing — that's why 1 thread × batch=64 (233 docs/sec) beats 8 threads × batch=128 (147 docs/sec) by a clear margin.
If your workload is naturally one-row-at-a-time — web requests, queue consumers, MCP servers — just use INSERT INTO
. The single-thread / single-row floor of 72 docs/sec is already ~7× the old Candle path, low enough latency that this isn't a tier you need to optimise around any more.
Before vs after, across the whole grid
To make the before/after concrete, we also swept the full threads × batch
grid against the old Candle/trans
path on the same box, same weights:
Each X-axis tick is backend threads/batch-size. The left half (trans …) is the old Candle path — docs/sec sits at 5–11 across the entire grid no matter how many threads or how large the batch, while CPU is already pinned. The right half (onnx …) is the new path — docs/sec is an order of magnitude higher across the whole sweep. Within the new path: at small batches, adding client threads helps (1T/batch=1 = 72 → 8T/batch=1 = 143); at large batches, a single client thread wins (1T/batch=64 = 233 is the global peak).
Same sweep, but plotting efficiency (docs/sec per % CPU) alongside docs/sec. On the Candle ( trans) side, both lines hug the floor — the box is spending CPU without producing documents. On the ONNX (onnx) side, efficiency is highest at 1–2 threads with mid-sized batches, where each percent of CPU buys the most embeddings, and it stays well above the old path even as we crank threads up to 32.
What's next #
A few things are queued behind this work:
GPU path. The current ONNX setup is CPU-only. The_use_gpu
parameter is plumbed through but not yet wired to the ORT CUDA execution provider.Windows perf parity. We currently serialise on Windows because of an ORT threading bug. Once that bug is resolved upstream, Windows should get the same shared-session behaviour Linux/macOS already have.More architectures down the ONNX path. Right now ONNX is the path for BERT-family encoders. T5, causal-LM and quantized GGUF models still go through Candle for now.
Try it #
If your existing table is already pointed at an ONNX-capable model, the new path takes over once you upgrade to Manticore Search 27.1.5 or newer — no schema changes, no re-ingest. You should just see your INSERTs go faster.
If you're not on an ONNX model yet — or you want to move to a smaller / faster one to take maximum advantage of the new backend — note that you can't swap the model on an existing field. Manticore doesn't support altering MODEL_NAME
on an existing FLOAT_VECTOR
field, so migrating in place isn't an option. You have two practical paths to choose between, depending on what's easier in your setup:
Option A — dump, edit, reload. Even if you no longer have the original source data, you can mysqldump
the existing table to a SQL file, edit the CREATE TABLE
in that dump to point MODEL_NAME
at the ONNX-optimised model you want, and replay the dump into a fresh table. Manticore will re-embed every row through the new path on the way in.
Option B — add a new column alongside, rebuild, drop the old one. If you'd rather stay in SQL and avoid the dump round-trip, add a new FLOAT_VECTOR
column on the same table that points at the ONNX model, then trigger a one-shot re-embed of that column from the source text:
ALTER TABLE t ADD COLUMN v_new FLOAT_VECTOR KNN_TYPE='hnsw'
HNSW_SIMILARITY='l2'
MODEL_NAME='Xenova/all-MiniLM-L6-v2'
FROM='text_field';
ALTER TABLE t REBUILD EMBEDDINGS v_new;
-- once you've cut over reads to v_new, drop the old column
ALTER TABLE t DROP COLUMN v_old;
See the Rebuilding embeddings section of the docs for the exact syntax and constraints.
On brand-new tables, none of this matters — just pick an ONNX-optimised MODEL_NAME
from the start.
A good place to shop for ONNX-ready embedding models is the Xenova collection on Hugging Face
— these are pre-converted to ONNX and ready to drop into MODEL_NAME='...'
. Filter the list by the feature-extraction task to narrow it down to embedding-style models. Some sensible starting points:
Xenova/all-MiniLM-L6-v2
— small and fast, 384-dim, great default.Xenova/all-MiniLM-L12-v2
— the model we benchmarked in this post, 384-dim, a step up in quality.Xenova/bge-small-en-v1.5
— strong English retrieval, 384-dim.Xenova/multilingual-e5-small
— multilingual coverage, 384-dim.
If you aren't using auto-embeddings yet at all, the original announcement walks through the SQL from scratch.
💬 Slack community — we'd love to see how the new path holds up on your data.